一、sys — 系统相关的参数和函数
sys模块官方文档: https://docs.python.org/3/library/sys.html
- sys.argv:获取运行 Python 程序的命令行参数。其中 sys.argv[0] 通常就是指该 Python 程序,sys.argv[1] 代表为 Python 程序提供的第一个参数,sys.argv[2] 代表为 Python 程序提供的第二个参数……依此类推。
- sys.byteorder:显示本地字节序的指示符。如果本地字节序是大端模式,则该属性返回 big;否则返回 little。
- sys.copyright:该属性返回与 Python 解释器有关的版权信息。
- sys.executable:该属性返回 Python 解释器在磁盘上的存储路径。
- **sys.exit()**:通过引发 SystemExit 异常来退出程序。将其放在 try 块中不能阻止 finally 块的执行。
- sys.flags:该只读属性返回运行 Python 命令时指定的旗标。
- **sys.getfilesystemencoding()**:返回在当前系统中保存文件所用的字符集。
- **sys.getrefcount(object)**:返回指定对象的引用计数。前面介绍过,当 object 对象的引用计数为 0 时,系统会回收该对象。
- **sys.getrecursionlimit()**:返回 Python 解释器当前支持的递归深度。该属性可通过 - setrecursionlimit() 方法重新设置。
- **sys.getswitchinterval()**:返回在当前 Python 解释器中线程切换的时间间隔。该属性可通过 setswitchinterval() 函数改变。
- sys.implementation:返回当前 Python 解释器的实现。
- sys.maxsize:返回 Python 整数支持的最大值。在 32 位平台上,该属性值为 2**31-1;在 64 位平台上,该属性值为 2**63-1。
- sys.modules:返回模块名和载入模块对应关系的字典。
- sys.path:该属性指定 Python 查找模块的路径列表。程序可通过修改该属性来动态增加 Python 加载模块的路径。
- sys.platform:返回 Python 解释器所在平台的标识符。
- sys.stdin:返回系统的标准输入流——一个类文件对象。
- sys.stdout:返回系统的标准输出流——一个类文件对象。
- sys.stderr:返回系统的错误输出流——一个类文件对象。
- sys.version:返回当前 Python 解释器的版本信息。
- sys.winver:返回当前 Python 解释器的主版本号。
例:
1 | from sys import argv |
sys.path 也是很有用的一个属性,它可用于在程序运行时为 Python 动态修改模块加载路径。例如,如下程序在运行时动态指定加载 E:\Lethe 目录下的模块:
1 | import sys |
二、os — 操作系统接口模块
os模块官方文档:https://docs.python.org/3/library/os.html。
(1)os模块与目录相关的函数如下:
- **os.getcwd()**:获取当前目录。
- **os.chdir(path)**:改变当前目录。
- **os.fchdir(fd)**:通过文件描述利改变当前目录。该函数与上一个函数的功能基本相似,只是该函数以文件描述符作为参数来代表目录。
- **s.chroot(path)**:改变当前进程的根目录。
- **os.listdir(path)**:返回 path 对应目录下的所有文件和子目录。
- **os.mkdir(path[, mode])**:创建 path 对应的目录,其中 mode 用于指定该目录的权限。该 mode参数代表一个 UNIX 风格的权限,比如 0o777 代表所有者可读/可写/可执行、组用户可读/可写/可执行、其他用户可读/可写/可执行。
- **os.makedirs(path[, mode])**:其作用类似于 mkdir(),但该函数的功能更加强大,它可以边归创建目录。比如要创建 abc/xyz/wawa 目录,如果在当前目录下没有 abc 目录,那么使用 mkdir() 函数就会报错,而使用 makedirs() 函数则会先创建 abc,然后在其中创建 xyz 子目录,最后在 xyz 子目录下创建 wawa 子目录。
- **os.rmdir(path)**:删除 path 对应的空目录。如果目录非空,则抛出一个 OSError 异常。程序可以先用 os.remove() 函数删除文件。
- **os.removedirs(path)**:递归删除目录。其功能类似于 rmdir(),但该函数可以递归删除 abc/xyz/wawa 目录,它会从 wawa 子目录开始删除,然后删除 xyz 子目录,最后删除 abc 目录。
- **os.rename(src, dst)**:重命名文件或目录,将 src 重名为 dst。
- **os.renames(old, new)**:对文件或目录进行递归重命名。其功能类似于 rename(),但该函数可以递归重命名 abc/xyz/wawa 目录,它会从 wawa 子目录开始重命名,然后重命名 xyz 子目录,最后重命名 abc 目录。
除此之外,os.path 模块下提供了一些操作目录的方法,这些函数可以操作系统的目录本身。
os.path模块下的操作目录的常见函数的功能和用法:
1 | import os |
(2)os模块与文件访问相关的函数如下:
- **os.open(file, flags[, mode])**:打开一个文件,并且设置打开选项,mode 参数是可选的。该函数返回文件描述符。其中 flags 代表打开文件的旗标,它支持如下一个或多个选项:
- os.O_RDONLY:以只读的方式打开。
- os.O_WRONLY:以只写的方式打开。
- os.O_RDWR:以读写的方式打开。
- os.O_NONBLOCK:打开时不阻塞。
- os.O_APPEND:以追加的方式打开。
- os.O_CREAT:创建并打开一个新文件。
- os.O_TRUNC:打开一个文件并截断它的长度为0(必须有写权限)。
- os.O_EXCL:在创建文件时,如果指定的文件存在,则返回错误。
- os.O_SHLOCK:自动获取共享锁。
- os.O_EXLOCK:自动获取独立锁。
- os.O_DIRECT:消除或减少缓存效果。
- os.O_FSYNC:同步写入。
- os.O_NOFOLLOW:不追踪软链接。
- **os.read(fd, n)**:从文件描述符 fd 中读取最多 n 个字节,返回读到的字符串。如果文件描述符副对应的文件己到达结尾,则返回一个空字节串。
- **os.write(fd, str)**:将字节串写入文件描述符 fd 中,返回实际写入的字节串长度。
- **os.close(fd)**:关闭文件描述符 fd。
- **os.lseek(fd, pos, how)**:该函数同样用于移动文件指针。其中 how 参数指定从哪里开始移动,如果将 how 设为 0 或 SEEK_SET,则表明从文件开头开始移动;如果将 how 设为 1 或 SEEK_CUR,则表明从文件指针当前位置开始移动;如果将 how 设为 2 或 SEEK_END,则表明从文件结束处开始移动。上面几个函数同样可用于执行文件的读写,程序通常会先通过 os.open() 打开文件,然后调用 os.read()、os.write() 来读写文件,当操作完成后通过 os.close() 关闭文件。
- **os.fdopen(fd[, mode[, bufsize]])**:通过文件描述符 fd 打开文件,并返回对应的文件对象。
- **os.closerange(fd_low, fd_high)**:关闭从 fd_low(包含)到 fd_high(不包含)范围的所有文件描述符。
- **os.dup(fd)**:复制文件描述符。
- **os.dup2(fd,fd2)**:将一个文件描述符fd复制到另一个文件描述符fd2中。
- **os.ftruncate(fd, length)**:将 fd 对应的文件截断到 length 长度,因此此处传入的 length 参数不应该超过文件大小。
- **os.remove(path)**:删除 path 对应的文件。如果 path 是一个文件夹,则抛出 OSError 错误。如果要删除目录,则使用 os.rmdir()。
- **os.link(src, dst)**:创建从 src 到 dst 的硬链接。硬链接是 UNIX 系统的概念,如果在 Windows 系统中就是复制目标文件。
- **os.symlink(src, dst)**:创建从 src 到 dst 的符号链接,对应于 Windows 的快捷方式。
(3)os模块与权限相关的函数
- **os.access(path, mode)**:检查 path 对应的文件或目录是否具有指定权限。该函数的第二个参数可能是以下四个状态值的一个或多个值:
- os.F_OK:判断是否存在。
- os.R_OK:判断是否可读。
- os.W_OK:判断是否可写。
- os.X_OK:判断是否可执行。
- **os.chrnod(path, mode)**:更改权限。其中 mode 参数代表要改变的权限,该参数支持的值可以是以下一个或多个值的组合:
- stat.S_IXOTH:其他用户有执行权限。
- stat.S_IWOTH:其他用户有写权限。
- stat.S_TROTH:其他用户有读权限。
- stat.S_IRWXO:其他用户有全部权限。
- stat.S_IXGRP:组用户有执行权限。
- stat.S_IWGRP:组用户有写权限。
- stat.S_IRGRP:组用户有读权限。
- stat.S_IRWXG:组用户有全部权限。
- stat.S_IXUSR:所有者有执行权限。
- stat.S_IWUSR:所有者有写权限。
- stat.S_IRUSR:所有者有读权限。
- stat.S_IRWXU:所有者有全部权限。
- stat.S_IREAD:Windows 将该文件设为只读的。
- stat.S_IWRITE:Windows 将该文件设为可写的。
- os.chown(path, uid, gid):更改文件的所有者。其中 uid 代表用户 id,gid 代表组 id。该命令主要在 UNIX 文件系统下有效。
- os.fchmod(fd, mode):改变一个文件的访问权限,该文件由文件描述符 fd 指定。该函数的功能与 os.chmod() 函数的功能相似,只是该函数使用 fd 代表文件。
- os.fchown(fd, uid, gid):改变文件的所有者,该文件由文件描述符 fd 指定。该函数的功能与 os.chown() 函数的功能相似,只是该函数使用 fd 代表文件。
(4)os模块与进程相关的函数
- os.name:返回导入依赖模块的操作系统名称,通常可返回 ‘posix’、’nt’、 ‘java’ 等值其中之一。
- os.environ:返回在当前系统上所有环境变量组成的字典。
- **os.fsencode(filename)**:该函数对类路径(path-like)的文件名进行编码。
- **os.fsdecode(filename)**:该函数对类路径(path-like)的文件名进行解码。
- os.PathLike:这是一个类,代表一个类路径(path-like)对象。
- os.getenv(key, default=None):获取指定环境变量的值。
- **os.getlogin()**:返回当前系统的登录用户名。与该函数对应的还有 os.getuid()、os.getgroups()、os.getgid() 等函数,用于获取用户 ID、用户组、组 ID 等,这些函数通常只在 UNIX 系统上有效。
- **os.getpid()**:获取当前进程 ID。
- os.getppid():获取当前进程的父进程 ID。
- **os.putenv(key, value)**:该函数用于设置环境变量。
- **os.cpu_count()**:返回当前系统的 CPU 数量。
- os.sep:返回路径分隔符。
- os.pathsep:返回当前系统上多条路径之间的分隔符。一般在 Windows 系统上多条路径之间的分隔符是英文分号(;);在 UNIX 及类 UNIX 系统(如 Linux、Mac os X)上多条路径之间的分隔符是英文冒号(:)。
- os.linesep:返回当前系统的换行符。一般在 Windows 系统上换行符是“\r\n”:在 UNIX 系统上换行符是“\n”;在 Mac os X 系统上换行符是“\r”。
- **os.urandom(size)**:返回适合作为加密使用的、最多由 N 个字节组成的 bytes 对象。该函数通过操作系统特定的随机性来源返回随机字节,该随机字节通常是不可预测的,因此适用于绝大部分加密场景。
在 os 模块下与进程管理相关的函数如下:
**os.abort()**:生成一个 SIGABRT 信号给当前进程。在 UNIX 系统上,默认行为是生成内核转储;在 Windows 系统上,进程立即返回退出代码 3。
os.execl(path, arg0, arg1, …):该函数还有一系列功能类似的函数,比如 os.execle()、os.execlp() 等,这些函数都是使用参数列表 arg0, arg1,…来执行 path 所代表的执行文件的。
由于 os.exec*() 函数都是 PosIX 系统的直接映射,因此如采使用该命令来执行 Python 程序,传入的 arg0 参数没有什么作用。os._exit(n) 用于强制退出 Python 解释器。将其放在 try 决中可以阻止 finally 块的执行。**os.forkpty()**:fork一个子进程。
**os.kill(pid, sig)**:将 sig 信号发送到 pid 对应的过程,用于结束该进程。
**os.killpg(pgid, sig)**:将 sig 信号发送到 pgid 对应的进程组。
**os.popen(cmd, mode=’r’, buffering=-1)**:用于向 cmd 命令打开读写管道(当 mode 为 r 时为只读管道,当 mode 为 rw 时为读写管道),buffering 缓冲参数与内置的 open() 函数有相同的含义。该函数返回的文件对象用于读写字符串,而不是字节。
**os.spawnl(mode, path, …)**:该函数还有一系列功能类似的函数,比如 os.spawnle()、os.spawnlp() 等,这些函数都用于在新进程中执行新程序。
**os.startfile(path[,operation])**:对指定文件使用该文件关联的工具执行 operation 对应的操作。如果不指定 operation 操作,则默认执行打开(open)操作。operation 参数必须是有效的命令行操作项目,比如 open(打开)、edit(编辑)、print(打印)等。
**os.system(command)**:运行操作系统上的指定命令。
三、random — 生成伪随机数
random模块官方文档:https://docs.python.org/3/library/random.html
在 random 模块下提供了如下常用函数:
- **random.seed(a=None, version=2)**:指定种子来初始化伪随机数生成器。
- **random.randrange(start, stop[, stop])**:返回从 start 开始到 stop 结束、步长为 step 的随机数。其实就相当于 choice(range(start, stop, step)) 的效果,只不过实际底层并不生成区间对象。
- **random.randint(a, b)**:生成一个范围为 a≤N≤b 的随机数。其等同于 randrange(a, b+1) 的效果。
- **random.choice(seq)**:从 seq 中随机抽取一个元素,如果 seq 为空,则引发 IndexError 异常。
- **random.choices(seq, weights=None, cum_weights=None, k=1)**:从 seq 序列中抽取 k 个元素,还可通过 weights 指定各元素被抽取的权重(代表被抽取的可能性高低)。
- **random.shuffle(x[, random])**:对 x 序列执行洗牌“随机排列”操作。
- **random.sample(population, k)**:从 population 序列中随机抽取 k 个独立的元素。
- **random.random()**:生成一个从0.0(包含)到 1.0(不包含)之间的伪随机浮点数。
- **random.uniform(a, b)**:生成一个范围为 a≤N≤b 的随机数。
- **random.expovariate(lambd)**:生成呈指数分布的随机数。其中 lambd 参数(其实应该是 lambda,只是 lambda 是 Python 关键字,所以简写成 lambd)为 1 除以期望平均值。如果 lambd 是正值,则返回的随机数是从 0 到正无穷大;如果 lambd 为负值,则返回的随机数是从负无穷大到 0。
例:
1 | import random |
四、time — 时间的访问和转换
time模块官方文档:https://docs.python.org/zh-cn/3/library/time.html#module-time
在日期、时间模块内常用的功能函数如下:
**time.asctime([t])**:将时间元组或 struct_time 转换为时间字符串。如果不指定参数 t,则默认转换当前时间。
**time.ctime([secs])**:将以秒数代表的时间转换为时间宇符串。
Python 可以用从 1970 年 1 月 1 日 0 点整到现在所经过的秒数来代表当前时间,比如我们写 30 秒,那么意味着时间是 1970 年 1 月 1 日 0 点 0 分 30 秒。但需要注意的是,在实际输出时可能会受到时区的影响,比如中国处于东八区,因此实际上会输出 1970 年 1 月 1 日 8 点 0 分 30 秒。**time.gmtime([secs])**:将以秒数代表的时间转换为 struct_time 对象。如果不传入参数,则使用当前时间。
**time.localtime([secs])**:将以秒数代表的时间转换为代表当前时间的 struct_time 对象。如果不传入参数,则使用当前时间。
**time.mktime(t)**:它是 localtime 的反转函数,用于将 struct_time 对象或元组代表的时间转换为从 1970 年 1 月 1 日 0 点整到现在过了多少秒。
**time.perf_counter()**:返回性能计数器的值。以秒为单位。
**time.process_time()**:返回当前进程使用 CPU 的时间。以秒为单位。
**time.sleep(secs)**:暂停 secs 秒,什么都不干。
**time.strftime(format[, t])**:将时间元组或 struct_time 对象格式化为指定格式的时间字符串。如果不指定参数 t,则默认转换当前时间。
**time.strptime(string[, format])**:将字符串格式的时间解析成 struct_time 对象。
**time.time()**:返回从 1970 年 1 月 1 日 0 点整到现在过了多少秒。
time.timezone:返回本地时区的时间偏移,以秒为单位。
time.tzname:返回本地时区的名字。
例:
1 | import time |
五、json — JSON 编码和解码器
json模块官方文档:https://docs.python.org/zh-cn/3/library/json.html#module-json
JSON 类型转换Python 类型的对应关系: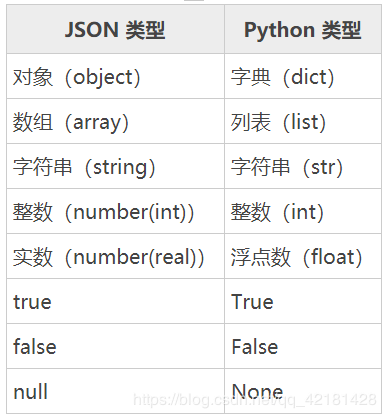
Python 类型转换 JSON 类型的对应关系:
json 模块中常用的函数和类的功能如下:
- **json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)**:将 obj 对象转换成 JSON 字符串输出到 fp 流中,fp 是一个支持 write() 方法的类文件对象。
- **json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan= True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)**:将 obj 对象转换为 JSON 字符串,并返回该JSON 字符串。
- **json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)**:从 fp 流读取 JSON 字符串,将其恢复成 JSON 对象,其中 fp 是一个支持 write() 方法的类文件对象。
- **json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)**:将 JSON 字符串 s 恢复成 JSON 对象。

dumps() 和 dump() 函数的 encode 操作(将 Python 对象转换成 JSON 字符串):
1 | import json |
loads() 和 load() 函数的 decode 操作(将 JSON 字符串转换成 Python 对象):
1 | import json |
六、re — 正则表达式操作
re模块官方文档:https://docs.python.org/zh-cn/3/library/re.html#module-re
- **re.compile(pattern, flags=0)**:该函数用于将正则表达式字符串编译成 _sre.SRE_Pattern 对象,该对象代表了正则表达式编译之后在内存中的对象,它可以缓存并复用正则表达式字符串。如果程序需要多次使用同一个正则表达式字符串,则可考虑先编译它。
- **re.match(pattern, string, flags=0)**:尝试从字符串的开始位置来匹配正则表达式,如果从开始位置匹配不成功,match() 函数就返回 None 。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。该函数返回 _sre.SRE_Match 对象,该对象包含的 span(n) 方法用于获取第 n+1 个组的匹配位置,group(n) 方法用于获取第 n+1 个组所匹配的子串
- **re.search(pattern, string, flags=0)**:扫描整个字符串,并返回字符串中第一处匹配 pattern 的匹配对象。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。该函数也返回 _sre.SRE_Match 对象。
match() 与 search() 的区别在于,match() 必须从字符串开始处就匹配,但 search() 可以搜索整个字符串。例如如下程序:
1 | import re |
- re.findall(pattern, string, flags=0):扫描整个字符串,并返回字符串中所有匹配 pattern 的子串组成的列表。其中 pattern 参数代表正则表达式;string 代表被匹配的宇符串;flags 则代表正则表达式的匹配旗标。
- re.finditer(pattern, string, flags=0):扫描整个字符串,并返回字符串中所有匹配 pattern 的子串组成的迭代器,迭代器的元素是 _sre.SRE_Match 对象。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。
对比 findall()、finditer() 和 search() 函数,search() 只返回字符串中第一处匹配 pattern 的子串;而 findall() 和 finditer() 则返回字符串中所有匹配 pattern 的子串。
- **re.fullmatch(pattem, string, flags=0)**:该函数要求整个字符串能匹配 pattern,如果匹配则返回包含匹配信息的 _sre.SRE_Match 对象;否则返回 None。
- **re.sub(pattern, repl, string, count=0, flags=0)**:该函数用于将 string 字符串中所有匹配 pattern 的内容替换成 repl;repl 既可是被替换的字符串,也可是一个函数。count 参数控制最多替换多少次,如果指定 count 为 0 ,则表示全部首换。
- **re.split(pattem, string, maxsplit=0, flags=0)**:使用 pattern 对 string 进行分割,该函数返回分割得到的多个子串组成的列表。其中 maxsplit 参数控制最多分割几次
- **re.purge()**:清除正则表达式缓存。
- **re.escape(pattern)**:对模式中除 ASCII 字符、数值、下画线(_)之外的其他字符进行转义。
re 模块中的 Match 对象(其具体类型为 _sre.SRE_Match)则是 match()、search() 方法的返回值,该对象中包含了详细的正则表达式匹配信息,包括正则表达式匹配的位置、正则表达式所匹配的子串。
sre.SRE_Match 对象包含了如下方法或属性:
- **match.group([group1,…])**:获取该匹配对象中指定组所匹配的字符串。
- **match.getitem(g)**:这是 match.group(g) 的简化写法。由于 match 对象提供了 getitem() 方法,因此程序可使用 match[g] 来代替 match.group(g)。
- **match.groups(default=None)**:返回 match 对象中所有组所匹配的字符串组成的元组。
- **match.groupdict(default= None)**:返回 match 对象中所有组所匹配的字符串组成的字典。
- **match.start([group])**:获取该匹配对象中指定组所匹配的字符串的开始位置。
- **match.end([group])**:获取该匹配对象中指定组所匹配的宇符串的结束位置。
- **match.span([group])**:获取该匹配对象中指定组所匹配的字符串的开始位置和结束位置。该方法相当于同时返回 start() 和 end() 方法的返回值。