0x01 环境与应用的基本结构 一、虚拟环境配置 1.1 创建虚拟环境 Python 3 和 Python 2 解释器创建虚拟环境的方法有所不同。在 Python 3中,虚拟环境由 Python 标准库中的 venv 包原生支持。
使用如下命令创建虚拟环境:
1 python -m venv virtual-environment-name
-m venv 选项的作用是以独立的脚本运行标准库中的 venv 包,后面的参数为虚拟环境的名称。
例如,如下命令创建了一个名称为venv的虚拟环境:
命令执行完毕后,当前目录中会出现一个名为 venv 的子目录,这里就是一个全新的虚拟环境,包含这个项目专用的 Python 解释器。
1.2 激活虚拟环境 在Windows下,可以通过如下命令激活虚拟环境:
虚拟环境激活后,命令行的路径前会有(venv),此时在命令行中输入python,将调用虚拟环境中的解释器,而不是全局解释器。如果打开了多个命令提示符窗口,则在每个窗口中都要激活虚拟环境。
在命令提示符中输入deactivate,则可以退出当前虚拟环境,还原为PATH环境变量。
1.3 在虚拟环境中安装包 在激活虚拟环境后,同样可以使用pip包管理器来进行python包的安装。
可以使用pip freeze命令查看虚拟环境中安装了哪些包
1.4 踩坑 (1)我实在windows下进行的配置,因为电脑上同时安装了python2和python3,所以之前把python3的解释器名字改为了python3.exe,但是使用python3命令创建venv虚拟环境会报错,将python3.exe改回python.exe,再用python命令即可成功创建。
(2)在创建并激活虚拟环境后,发现解释器和pip管理器依然是全局的,后来将路径中的中文去掉,使用全英文路径即可。
<br>
二、应用的基本结构 2.1 初始化 所有Flask应用都必须创建一个应用实例,应用实例是Flask类的对象,通常由下述代码创建:
1 2 from flask import Flaskapp = Flask(__name__)
Flask 类的构造函数只有一个必须指定的参数,即应用主模块或包的名称。在大多数应用中,Python 的 __name__ 变量就是所需的值。
2.2 路由和视图函数 处理 URL 和函数之间关系的程序称为路由 。在 Flask 应用中定义路由的最简便方式,是使用应用实例提供的app.route 装饰器。、
下面的例子说明了如何使用这个装饰器声明路由,其将index()函数注册为根地址的处理程序:
1 2 3 @app.route('/' def index (): return '<h1>Hello World!</h1>'
除此之外,还能使用动态的路由:
1 2 3 @app.route('/user/<name>' def user (name ): return '<h1>Hello, {}!</h1>' .format (name)
路由的<name>中的内容就是动态部分,任何能匹配静态部分的 URL 都会映射到这个路由上。调用视图函数时,Flask 会将动态部分作为参数传入函数。
路由中的动态部分默认使用字符串,不过也可以是其他类型。/user/<int:id> 只会匹配动态片段 id 为整数的 URL,例如/user/123。
2.3 一个完整的应用 使用一个应用实例、一个路由和一个视图函数可以组成一个完整的Flask应用hello.py:
1 2 3 4 5 6 from flask import Flaskapp = Flask(__name__) @app.route('/' def index (): return '<h1>Hello World!</h1>'
2.4 Web开发服务器 若想启动上面编写的hello.py应用,首先激活虚拟环境。
(1)Linux和macOS用户使用如下命令:
1 2 export FLASK_APP=hello.pyflask run
(2)在Windows下
如果你的 Terminal 用的是 cmd,则使用如下命令:
1 2 set FLASK_APP=hello.pyflask run
如果你的 Terminal 用的是 powershell,则使用如下命令:
1 2 $env :FLASK_APP=".\hello.py" flask run
默认的端口是5000,此时再访问http:localhost:5000/即可
2.5 动态路由 在hello.py的基础上增加一个动态路由:
1 2 3 4 5 6 7 8 9 10 from flask import Flaskapp = Flask(__name__) @app.route('/' def index (): return '<h1>Hello World!</h1>' @app.route('/user/<name>' def users (name ): return '<h1>Hello {}</h1>' .format (name)
此时访问http://localhost:5000/user/Lethe,则会显示Hello Lethe
2.6 调试模式 调试模式默认禁用,若想启用,在执行 flask run 命令之前设定环境遍历 FLASK_DEBUG=1即可。
千万不要在生产服务器中启用调试模式。
2.7 命令行选项 (1)flask shell 命令在应用的上下文中打开一个 Python shell 会话。在这个会话中可以运行维护任务或测试,也可以调试问题。
(2)flask run 命令我们已经用过,它的作用是在 Web开发服务器中运行应用,可以使用 flask run –help查看该命令的具体参数使用。
其中 --host参数可以告诉Web服务器在哪个网络接口上监听客户端发来的连接。默认情况下,Flask 的 Web 开发服务器监听 localhost 上的连接。要写监听公网上的连接,则需要如下启动命令:
1 flask run --host 0.0.0.0
2.8 请求-响应循环 2.8.1 应用和请求上下文 在 Flask 中有两种上下文:应用上下文 和请求上下文。
应用上下文包括:
current_app:当前应用的应用实例
g:处理请求时用作临时存储的对象,每次请求都会重设这个
请求上下文包括:
request:请求对象,封装了客户端发出的 HTTP 请求中的内容
session:用户会话,值为一个字典,存储请求之间需要“记住”的值
Flask 在分派请求之前激活(或推送 )应用和请求上下文,请求处理完成后再将其删除。应用上下文被推送后,就可以在当前线程中使用current_app 和 g 变量。类似地,请求上下文被推送后,就可以使用request 和 session 变量。如果使用这些变量时没有激活应用上下文或请求上下文,就会导致错误。
由于这一部分对于初学者来说比较难理解,推荐阅读此文章:http://www.bjhee.com/flask-ad1.html
2.8.2 请求对象 Flask 通过上下文变量 request 对外开放请求对象,此对象包含客户端发送的HTTP请求的全部信息。
Flask请求对象常用属性和方法如下:
form:一个字典,存储请求提交的所有表单字段
args:一个字典,存储通过 URL 查询字符串传递的所有参数
values:一个字典, form 和 args 的合集
cookies: 一个字典,存储请求的所有 cookie
headers :一个字典,存储请求的所有 HTTP 首部
files: 一个字典,存储请求上传的所有文件
get_data(): 返回请求主体缓冲的数据
get_json(): 返回一个 Python 字典,包含解析请求主体后得到的 JSON
blueprint:处理请求的 Flask 蓝本的名称;蓝本在第 7 章介绍
endpoint:处理请求的 Flask 端点的名称;Flask 把视图函数的名称用作路由端点的名称
method: HTTP 请求方法,例如 GET 或 POST
scheme: URL 方案( http 或 https )
is_secure(): 通过安全的连接(HTTPS)发送请求时返回 True
host: 请求定义的主机名,如果客户端定义了端口号,还包括端口号
path: URL 的路径部分
query_string: URL 的查询字符串部分,返回原始二进制值
full_path: URL 的路径和查询字符串部分
url: 客户端请求的完整 URL
base_url: 同 url ,但没有查询字符串部分
remote_addr: 客户端的 IP 地址
environ: 请求的原始 WSGI 环境字典
2.8.3 请求钩子 请求钩子通过装饰器实现,可以将某个函数装饰为一个请求钩子,在请求开始或结束时自动调用被修饰的函数内容。
Flask 支持以下 4 种钩子:
before_request:注册一个函数,在每次请求之前运行。
before_first_request:注册一个函数,只在处理第一个请求之前运行。可以通过这个钩子添加服务器初始化任务。
after_request:注册一个函数,如果没有未处理的异常抛出,在每次请求之后运行。
teardown_request:注册一个函数,即使有未处理的异常抛出,也在每次请求之后运行。
2.8.4 响应 (1)Flask 调用视图函数后,会将其返回值作为响应的内容。
可以通过设置返回值的第二个参数来返回不同的状态码,如返回400:
1 2 3 @app.route('/' def index (): return '<h1>Bad Request</h1>' , 400
视图函数返回的响应还可接受第三个参数,这是一个由 HTTP 响应首部组成的字典。
(2)除此之外,还可以返回一个响应对象。make_response() 函数接收与返回值一样的参数,然后返回一个响应对象。
这么做的目的是可以通过此返回对象调用各个方法,进一步设置相应。
如下创建一个相应对象,然后设置cookie:
1 2 3 4 5 6 7 8 from flask import Flask, make_responseapp = Flask(__name__) @app.route('/' def index (): response = make_response('<h1>This document carries a cookie!<h1/>' ) response.set_cookie('answer' , '42' ) return response
这样在访问时,返回的同时也会设置一个cookie。
Flask响应对象常用的属性和方法如下:
status_code: HTTP 数字状态码
headers:一个类似字典的对象,包含随响应发送的所有首部
set_cookie(): 为响应添加一个 cookie
delete_cookie(): 删除一个 cookie
content_length: 响应主体的长度
content_type: 响应主体的媒体类型
set_data(): 使用字符串或字节值设定响应
get_data(): 获取响应主体
(3)重定向
1 2 3 4 5 6 from flask import Flask, redirectapp = Flask(__name__) @app.route('/' def index (): return redirect('http://www.baidu.com' )
(4)处理错误
1 2 3 4 5 6 7 8 from flask import Flask, abortapp = Flask(__name__) @app.route('/answer/<int:id>' def get_user (id if id != 1 : abort(404 ) return '<h1>answer=1</h1>'
上例访问 /user/1时会返回answer=1,若<id>不1,则返回404。
<br>
0x02 模板 一、Jinja2模板引擎 1.1 变量 默认情况下,Flask 在应用目录中的 template 子目录中寻找模板。
在模板中使用 {{}} 结构来表示一个变量,是一种特殊的占位符,告诉模板引擎这个位置的值从渲染模板时使用的数据中获取。
index.html:
1 < h1>Hello World!< /h1>
user.html:
1 < h1>Hello, {{ name }}!< /h1>
hello.py
1 2 3 4 5 6 7 8 9 10 from flask import Flask, render_templateapp = Flask(__name__) @app.route('/' def index (): return render_template('index.html' ) @app.route('/user/<name>' def user (name ): return render_template('user.html' , name=name)
Jinja2 能识别所有类型的变量,甚至是一些复杂的类型,例如列表、字典和对象。下面是在模板中使用变量的一些示例:
1 2 3 4 < p>A value from a dictionary: {{ mydict['key'] }}.< /p>< p>A value from a list: {{ mylist[3] }}.< /p>< p>A value from a list, with a variable index: {{ mylist[myintvar] }}.< /p>< p>A value from an object's method: {{ myobj.somemethod() }}.< /p>
变量的值可以使用过滤器修改。过滤器添加在变量名之后,二者之间以竖线分隔。
Jinjia2变量过滤器:
过滤器名
说明
safe
渲染值时不转义
capitalize
把值的首字母转换成大写,其他字母转换成小写
lower
把值转换成小写形式
upper
把值转换成大写形式
title
把值中每个单词的首字母都转换成大写
trim
把值的首尾空格删掉
striptags
渲染之前把值中所有的 HTML 标签都删掉
1.2 控制结构 (1)条件判断语句
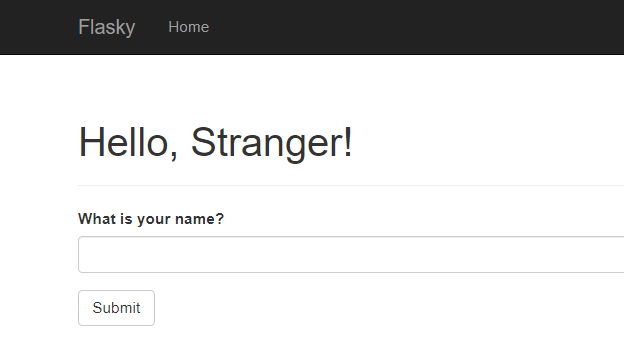
1 2 3 4 5 {% if user %} Hello, {{ user }}! {% else %} Hello, Stranger! {% endif %}
(2)for循环语句
1 2 3 4 5 < ul> {% for comment in comments %} < li>{{ comment }}< /li> {% endfor %} < /ul>
(3)宏
Jinja2支持宏,类似于函数的作用,例如:
1 2 3 4 5 6 7 8 9 {% macro render_comment(comment) %} < li>{{ comment }}< /li>{% endmacro %} < ul>{% for comment in comments %} {{ render_comment(comment) }} {% endfor %} < /ul>
还可以把宏保存在单独文件中,然后重复使用,如
macors.html:
1 2 3 4 {% macro render_comment(comment) %} < li>{{ comment }}< /li>{% endmacro %} < ul>
然后再需要用到宏的模板中使用 import 语句导入:
1 2 3 4 5 6 {% import 'macros.html' as macros %} < ul> {% for comment in comments %} {{ macros.render_comment(comment) }} {% endfor %} < /ul>
(4)模板
需要在多处重复使用的模板代码片段可以写入单独的文件,再引入所有模板中,以以避免重复:
1 {% include 'common.html' %}
模板也是可以继承 的,先创建一个基模板 base.html 如下:
1 2 3 4 5 6 7 8 9 10 11 < html> < head> {% block head %} < title>{% block title %}{% endblock %} - My Application< /title> {% endblock%} < /head> < body> {% block body %} {% endblock %} < /body>< /html>
上面 block 和endblock 定义的区块中内容可以在衍生模板中覆盖,如下:
1 2 3 4 5 6 7 8 9 10 {% extends "base.html" %} {% block title%}Index{% endblock %} {% block head %} {{ super() }} < style> < /style> {% endblock %} {% block body %} < h1>Hello, World!< /h1>{% endblock %}
extends 声明此模板衍生自 base.html,然后将基模板中定义的3个区块重新覆盖,在衍生模板的区块里可以调用 super()来使用基模板中的内容。
<br>
二、使用Flask-Bootstrap集成Bootstrap 使用前需要先初始化Flask-Bootstrap,如下
1 2 3 from flask_bootstrap import Bootstrapbootstrap = Bootstrap(app)
然后可以直接继承提供的 bootstrap/base.html 模板,其是一个包含了Bootstrap 文件和一般结构的基模板,衍生模板 user.html如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 {% extends "bootstrap/base.html" %} {% block title %}Flasky{% endblock %} {% block navbar %} < div class="navbar navbar-inverse" role="navigation"> < div class="container"> < div class="navbar-header"> < button type="button" class="navbar-toggle" data-toggle="collapse" data-target=".navbar-collapse"> < span class="sr-only">Toggle navigation< /span> < span class="icon-bar">< /span> < span class="icon-bar">< /span> < span class="icon-bar">< /span> < /button> < a class="navbar-brand" href="/">Flasky< /a> < /div> < div class="navbar-collapse collapse"> < ul class="nav navbar-nav"> < li>< a href="/">Home< /a>< /li> < /ul> < /div> < /div> < /div>{% endblock %} {% block content %} < div class="container"> < div class="page-header"> < h1>Hello, {{ name }}!< /h1> < /div> < /div>{% endblock %}
完整hello.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 from flask import Flask, render_templatefrom flask_bootstrap import Bootstrapapp = Flask(__name__) bootstrap = Bootstrap(app) @app.route('/' def index (): return render_template('index.html' ) @app.route('/user/<name>' def user (name ): return render_template('user.html' , name=name)
Flask-Bootstrap基模板中定义的区块如下:
区块名
说明
doc
整个 HTML 文档
html_attribs
<html> 标签的属性
html
<html> 标签中的内容
head
<head> 标签中的内容
title
<title> 标签中的内容
metas
一组 <meta> 标签
styles
CSS 声明
body_attribs
<body> 标签的属性
body
<body> 标签中的内容
navbar
用户定义的导航栏
content
用户定义的页面内容
scripts
文档底部的 JavaScript 声明
若要在衍生模块中添加新的JavaScript文件,为了防止覆盖掉原有的引入Bootstrap的内容,需要使用 super() 函数:
1 2 3 4 {% block scripts %} {{ super() }} < script type="text/javascript" src="my-script.js">< /script>{% endblock %}
<br>
三、自定义错误页面 通常的错误页面有如下两种:
404:客户端请求未知页面或路由时显示
500:有未处理的异常时显示
使用 app.errorhandler 装饰器为这两个错误提供自定义的处理函数:
1 2 3 4 5 6 7 @app.errorhandler(404 def pate_not_found (e ): return render_template('404.html' ), 404 @app.errorhandler(500 def internal_server_error (e ): return render_template('500.html' ), 500
为了减少代码重复,我们可以在上面的基础上改进一下 base.html,使其成为继承了 bootstrap/base.html 的二级基模板,也可以被其他模板继承。
二级模板 templates/base.html:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 {% extends "bootstrap/base.html" %} {% block title %}Flasky{% endblock %} {% block navbar %} < div class="navbar navbar-inverse" role="navigation"> < div class="container"> < div class="navbar-header"> < button type="button" class="navbar-toggle" data-toggle="collapse" data-target=".navbar-collapse"> < span class="sr-only">Toggle navigation< /span> < span class="icon-bar">< /span> < span class="icon-bar">< /span> < span class="icon-bar">< /span> < /button> < a class="navbar-brand" href="/">Flasky< /a> < /div> < div class="navbar-collapse collapse"> < ul class="nav navbar-nav"> < li>< a href="/">Home< /a>< /li> < /ul> < /div> < /div> < /div>{% endblock %} {% block content %} < div class="container"> {% block page_content %}{% endblock %} < /div>{% endblock %}
这样,应用中的模板继承自这个模板即可。
templates/404.html
1 2 3 4 5 6 7 8 9 {% extends "base.html" %} {% block title %}Flasky - Page Not Found{% endblock %} {% block page_content %} < div class="page-header"> < h1>Not Found< /h1> < /div>{% endblock %}
上面的 user.html 也可以继承改模板来简化:
1 2 3 4 5 6 7 8 9 {% extends "base.html" %} {% block title %}Flasky{% endblock %} {% block page_content %} < div class="page-header"> < h1>Hello, {{ name }}!< /h1> < /div>{% endblock %}
<br>
四、链接 有时需要用动态路由链接多个不同的页面,此时就可以使用 url_for() 辅助函数,它使用应用的 URL 映射中保存的信息生成URL。
用法如下:
(1)以视图名为参数,返回对应的URL
返回根URL /
(2)使用参数 _external 可返回绝对地址
1 url_for('index' , _external=True )
返回绝对地址 http://localhost:5000/
(3)生成动态URL,将动态部分作为关键词参数传入
1 url_for('user' , name='john' , _external=True )
返回结果是 http://localhost:5000/user/john
(4)还可以添加非动态参数到查询字符串中
1 url_for('user' , name='john' , pate=2 , version=1 )
返回结果是 /user/john?page=2&version=1
<br>
五、静态文件 Flask路由中有一个特殊路由 static 路由:/static/<filename>
1 url_for('static' , filename='css/styles.css' , _external=True )
返回的结果是 http://localhost:5000/static/css/styles.css
Flask默认在根目录中名为 static 的子目录中寻找静态文件。
下例说明了在应用的基模板中引入 favicon.ico 图标:
templates/base.html
1 2 3 4 5 {% block head %} {{ super () }} <link rel="shortcut icon" href="{{ url_for('static', filename='favicon.ico') }}" , type ="image/x-icon" > <link rel="shortcut icon" href="{{ url_for('static', filename='favicon.ico') }}" , type ="image/x-icon" > {% endblock %}
<br>
六、使用Flask-Moment本地化日期和时间 服务器一般使用协调世界时(UTC)来统一时间,但是把时间发送个Web浏览器时需要转换成当地时间,然后用Javascript渲染。
Flask-Moment是一个Flask扩展,能简化把Moment.js 集成到 Jinja2 模板中的过程。
使用pip在虚拟环境中安装 flask-moment 之后同样需要进行初始化
1 2 from flask_moment import Momentmoment = Moment(app)
除了Moment.js, Flask-Moment 还依赖 jQuery.js。因此要在 HTML 文档的某个地方引入这两个库。Bootstrap 已经引入了 jQuery.js,因此只需引入 Moment.js 即可。
在基模板中的 scripts 块中引入这个库,同时保留原始内容。
1 2 3 4 {% block scripts %} {{ super () }} {{ moment.include_moment() }} {% endblock %}
为了处理时间戳,Flask-Moment 向模板开放了 moment 对象,下例把变量 current_time 传入模板进行渲染:
hello.py:
1 2 3 4 5 6 7 8 9 10 11 12 from flask import Flask, render_templatefrom flask_bootstrap import Bootstrapfrom flask_moment import Momentfrom datetime import datetimeapp = Flask(__name__) bootstrap = Bootstrap(app) moment = Moment(app) @app.route('/' def index (): return render_template('index.html' , current_time=datetime.utcnow())
然后在index.html 中渲染模板变量 current_time
templates/index.html
1 2 3 4 5 6 7 8 9 10 11 12 13 {% extends "base.html" %} {% block title %}Flasky{% endblock %} {% block page_content %} < div class="page-header"> < h1>Hello World!< /h1> < /div>< p>The local date and time is {{ moment(current_time).format('LLL') }}.< /p>< p>That was {{ moment(current_time).fromNow(refresh=True) }}< /p>{% endblock %}
format('LLL') 函数根据客户端计算机中的时区和区域设渲染日期和时间。参数决定了渲染的方式,从 'L' 到 'LLLL' 分别对应不同的复杂度。format() 函数还可接受很多自定义的格式说明符。
第二行中的 fromNow() 渲染相对时间戳,而且会随着时间的推移自动刷新显示的时间。这个时间戳最开始显示为 a few seconds ago,但设定 refresh=True 参数后,其内容会随着时间的推移而更新。
Moment.js文档:http://momentjs.com/docs/#/displaying/
效果如下:
另外,Flask-Moment渲染的时间还可以实现多种语言的本地化,方法时在引入 Moment.js 后, 立即把两个字母的语言代码传给 locale() 函数,如西班牙语方式:
1 2 3 4 5 {% block scripts %} {{ super () }} {{ moment.include_moment() }} {{ moment.locale('es' ) }} {% endblock %}
<br>
0x03 表单 在Flask中,通常使用Flask-WTF扩展来对Web表单进行处理,这样更加方便。首先在虚拟环境中安装此扩展:
一、配置 Flask-WTF扩展不用在应用层初始化,但是需要配置一个密钥(SECRET_KEY),Flask 使用这个密钥保护用户会话,以防被篡改,也就是防止 CSRF 攻击。
1 2 app = Flask(_name__) app.config['SECRET_KEY' ] = 'I am Lethe'
app.config 字典可用于存储 Flask、扩展和应用自身的配置变量。实际上为了增强安全性,密钥不应该直接写入源码,而要保存在环境变量中。
<br>
二、表单类 使用Flask-WTF时,服务端的每个Web表单都由一个继承自 FlaskForm 的类表示。这个类定义表单中的一组字段,每个字段都用对象表示。字段对象可附属一个或多个验证函数 。验证函数用于验证用户提交的数据是否有效。
下面的表单示例中包含一个文本字段和一个提交按钮:
1 2 3 4 5 6 7 from flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredclass NameForm (FlaskForm ): name = StringField('What is your name?' , validator=[DataRequired()]) submit = SubmitField('Submit' )
上面代码中:
StringField 类表示属性为 type="text" HTML <input> 元素。
SubmitField 类表示属性为 type="submit" 的HTML元素 <input> 元素。
字段构造函数的第一个参数代表使用的标注(label)
StringField 构造函数中的可选参数 validators 指定一个由验证函数组成的列表,在接收数据前对数据进行验证(DataRequired 确保提交的数据不为空)
WTForms 支持的 HTML 标准字段:
字段类型
说明
BooleanField
复选框,值为 True 和 False
DateField
文本字段,值为 datetime.date 格式
DateTimeField
文本字段,值为 datetime.datetime 格式
DecimalField
文本字段,值为 decimal.Decimal
FileField
文件上传字段
HiddenField
隐藏的文本字段
MultipleFileField
多文件上传字段
FieldList
一组指定类型的字段
FloatField
文本字段,值为浮点数
FormField
把一个表单作为字段嵌入另一个表单
IntegerField
文本字段,值为整数
PasswordField
密码文本字段
RadioField
一组单选按钮
SelectField
下拉列表
SelectMultipleField
下拉列表,可选择多个值
SubmitField
表单提交按钮
StringField
文本字段
TextAreaField
多行文本字段
WTForms 验证函数:
验证函数
说明
DataRequired
确保转换类型后字段中有数据
Email
验证电子邮件地址
EqualTo
比较两个字段的值;常用于要求输入两次密码进行确认的情况
InputRequired
确保转换类型前字段中有数据
IPAddress
验证 IPv4 网络地址
Length
验证输入字符串的长度
MacAddress
验证 MAC 地址
NumberRange
验证输入的值在数字范围之内
Optional
允许字段中没有输入,将跳过其他验证函数
Regexp
使用正则表达式验证输入值
URL
验证 URL
UUID
验证 UUID
AnyOf
确保输入值在一组可能的值中
NoneOf
确保输入值不在一组可能的值中
<br>
三、表单渲染 表单字段是可调用的,在模板中调用后会渲染成HTML。假设视图函数通过 form 参数把上面的 NameForm 实例传入模板,在模板中可以生成一个简单的HTML表单,如下:
1 2 3 4 5 < form method="POST"> {{ form.hidden_tag() }} {{ form.name.label }} {{ form.name() }} {{ form.submit() }} < /form>
这里的 form.hidden_tag() 元素生成一个隐藏的字段,用于 CSRF 防护。
在调用字段的时候,传入的关键词参数将转换为字段的HTML属性 。 如下,指定id或class属性,从而可以定义CSS样式:
1 2 3 4 5 < form method="POST"> {{ form.hidden_tag() }} {{ form.name.label }} {{ form.name(id='my-text-field') }} {{ form.submit() }} < /form>
在实际渲染及美化表单时,可以直接使用 Bootstrap 的表单样式,通过Flask-Bootstrap扩展,如下:
1 2 {% import "bootstrap/wtf.html" as wtf %} {{ wtf.quick_form(from ) }}
使用 import 导入 bootstrap/wtf.html 文件,其中定义了一个用默认Bootstrap 样式渲染的 Flask-WTF 表单对象的辅助函数 wtf.quick_form() ,参数为Flask-WTF 表单对象。
使用Flask-WTF 和 Flask-Bootstrap渲染表单,templates/index.html:
1 2 3 4 5 6 7 8 9 10 11 {% extends "base.html" %} {% import "bootstrap/wtf.html" as wtf %} {% block title %}Flasky{% endblock %} {% block page_content %} < div class="page-header"> < h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!< /h1> < /div>{{ wtf.quick_form(form) }} {% endblock %}
<br>
四、处理表单 定义了表单的类,需要在视图函数中对表单进行处理和渲染,下例使用 GET 和 POST 方法处理表单:
hello.py
1 2 3 4 5 6 7 8 @app.route('/' , methods=['GET' , 'POST' ] def index (): name = None form = NameForm() if form.validate_on_submit(): name = form.name.data form.name.data = '' return render_template('index.html' , form=form, name=name)
局部变量 name 用于存放表单中的名字字段,默认值为 None。
validate_on_submit() 方法:提交表单后,数据能被所有验证函数接收,返回True;否则返回False。最后用 render_template() 渲染表单时,将变量name,和对象form传入到模板中。
效果如下:
五、重定向和用户会话 在实际情况中,最好别让Web应用把 POST 请求作为浏览器发送的最后一个请求,因此可以使用重定向作为POST请求的响应。
如在用POST方式提交完表单后,再向重定向的URL发送GET请求,显示页面的内容,用户不会察觉到有所不同,这叫做 “POST / 重定向 / GET” 模式。
在这种模式下,应用处理POST请求时,需要用变量保存输入的数据,否则一旦重定向后,就无法再通过form.name.data获取POST请求中的字段值。
应用也可以把数据存储在用户会话(session)中,以便在请求之间“记住”数据。用户会话是一种私有存储,每个连接到服务器的客户端都可访问。
改进后的hello.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from flask import Flask, render_template, session, redirect, url_forfrom flask_bootstrap import Bootstrapfrom flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredapp = Flask(__name__) bootstrap = Bootstrap(app) app.config['SECRET_KEY' ] = 'I am Lethe' class NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' ) @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): session['name' ] = form.name.data return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ))
相比于上一个例子中,将 name保存在局部变量中,这里将其保存在了用户会话中,即 session[‘name’]。
若表单数据有效,则会用 redirect() 函数进行重定向,其参数为URL,因此可以使用辅助函数 url_for() 来生成URL,这里即重定向到根URL。
视图函数在向模板传参时,通过 session.get(‘name’) 从session中取出数据
<br>
六、闪现消息 请求完成后,有时需要向用户发送一些提示信息,如用户名或密码无效等,这可以用到闪现消息。
Flask中通过 flash() 函数实现此功能:
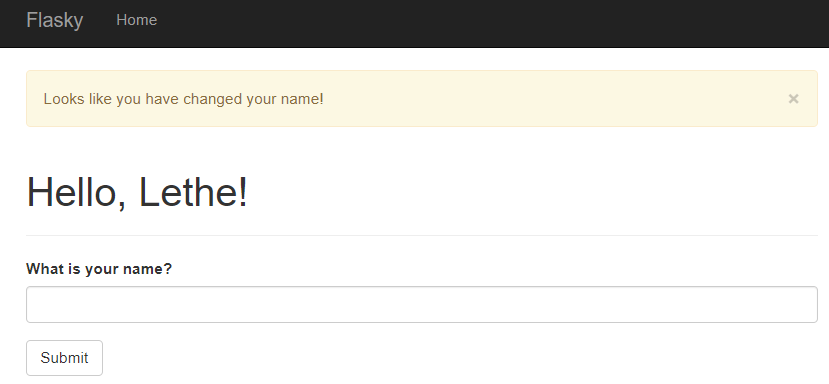
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from flask import Flask, render_template, session, redirect, url_for, flashfrom flask_bootstrap import Bootstrapfrom flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredfrom flask_moment import Momentapp = Flask(__name__) bootstrap = Bootstrap(app) moment = Moment(app) app.config['SECRET_KEY' ] = 'I am Lethe' class NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' ) @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): old_name = session.get('name' ) if old_name is not None and old_name != form.name.data: flash('Looks like you have changed your name!' ) session['name' ] = form.name.data return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ))
当两次提交的name不一样时,就会调用 flash()函数,在发给客户端的下一个响应中显示一个消息。
仅调用 flash() 函数不能将消息显示出来,还需要经过模板的渲染。最好在基模板中渲染闪现消息,这样继承自它的所有页面都能显示要闪现的消息。
Flask中用 get_flashed_message() 函数在模板中获取并渲染闪现消息,如下修改emplates/base.html中的 content 块:
1 2 3 4 5 6 7 8 9 10 11 {% block content %} < div class="container"> {% for message in get_flashed_message() %} < div class="alert alert-warning"> < button type="button" class="close" data-dismiss="alert">× < /button> {{ message }} < /div> {% endfor %} {% block page_content %}{% endblock %} < /div>{% endblock %}
此实例使用Bootstrap 提供的 CSS alert 样式渲染警告消息。
使用了循环,因为在之前的请求循环中每次调用 flash() 函数时都会生成一个消息,所以可能有多个消息在排队等待显示。
get_flashed_messages() 函数获取的消息在下次调用时不会再次返回,因此闪现消息只显示一次,然后就消失了
两次提交不同的值,效果如下:
<br>
0x04 数据库 这里我们使用 Flask-SQLAlchemy 扩展来进行数据库操作,SQLAlchemy 是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
同样现在虚拟环境中安装此扩展:
1 pip install flask-sqlalchemy
一、配置 在 Flask-SQLAlchemy 中,数据库使用 URL 指定,如下:
数据库引擎
URL
MySQL
mysql://username:password@hostname/database
Postgres
postgresql://username:password@hostname/database
SQLite(Linux,macOS)
sqlite:////absolute/path/to/database
SQLite(Windows)
sqlite:///c:/absolute/path/to/database
hostname:数据库服务所在的主机
database:要使用的数据库名
username:数据库用户名
password:数据库密码
注意:
SQLite 数据库没有服务器,因此不用指定 hostname、username 和 password。URL 中的 database 是磁盘中的文件名。
使用的数据库URL必须保存到 Flask 配置对象的 SQLALCHEMY_DATABASE_URI 键中。
建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键设为 False,以便在不需要跟踪对象变化时降低内存消耗。
数据库配置示例:
1 2 3 4 5 6 7 8 9 10 11 import osfrom flask_sqlalchemy import SQLAlchemybasedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI' ] = 'sqlite:///' + \ os.path.join(basedir, 'data.sqlite' ) app.config['SQLALCHEMY_TRACK_MODIFICATIONS' ] = False db = SQLAlchemy(app)
<br>
二、定义模型 在 ORM(对象关系映射器)中,模型一般是一个 Python 类,类中的属性对应于数据库表中的列。Flask-SQLAlchemy 实例为模型提供了一个基类以及一系列辅助类和辅助函数,可用于定义模型的结构。
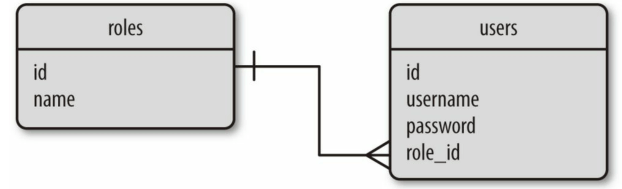
如下实体 – 关系图中的 roles 表和 users 表,我们可以分别定义为 Role 和 User 模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Role (db.Model): __tablename__ = 'roles' id = db.Column(db.Integer, primary_key=True ) name = db.Column(db.String(64 ), unique=True ) def __repr__ (self ): return '<Role %r>' % self.name class User (db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True ) username = db.Column(db.String(64 ), unique=True , index=True ) def __repr__ (self ): return '<User %r>' % self.username
类变量 __tablename__ 定义在数据库中使用的表名,如不定义,则会使用默认的表名。
db.Column 类构造函数的第一个参数是数据库列和模型的类型,其他参数则是一些列选项,如主键(primary_key)、索引(index)、不允许重复(unique)等。__repr()__ 方法返回一个具有可读性的字符串表示模型,不是强制要求,可方便调试和测试。
(1)常用的 SQLAlchemy 列类型:
类型名
Python类型
说明
Integer
int
普通整数,通常是 32 位
SmallInteger
int
取值范围小的整数,通常是 16 位
BigInteger
int 或 long
不限制精度的整数
Float
float
浮点数
Numeric
decimal.Decimal
定点数
String
str
变长字符串
Text
str
变长字符串,对较长或不限长度的字符串做了优化
Unicode
unicode
变长 Unicode 字符串
UnicodeText
unicode
变长 Unicode 字符串,对较长或不限长度的字符串做了优化
Boolean
bool
布尔值
Date
datetime.date
日期
Time
datetime.time
时间
DateTime
datetime.datetime
日期和时间
Interval
datetime.timedelta
时间间隔
Enum
str
一组字符串
Pickle
Type
任何 Python 对象 自动使用 Pickle 序列化
LargeBinary
str
二进制 blob
(2)常用的 SQLAlchemy 列选项:
选项名
说明
primary_key
如果设为 True ,列为表的主键
uniquey
如果设为 True ,列不允许出现重复的值
indexy
如果设为 True ,为列创建索引,提升查询效率
nullabley
如果设为 True ,列允许使用空值;如果设为 False ,列不允许使用空值
defaulty
为列定义默认值
<br>
三、关系 关系型数据库使用关系把不同表中的行联系起来,上面那个关系图中表示的实际上是一种一对多关系,即一个角色可属于多个用户,而每个用户只能由一个角色。
在数据库模型中定义关系补充如下:
1 2 3 4 5 6 7 class Role (db.Model): users = db.relationship('User' , backref='role' ) class User (db.Model): role_id = db.Column(db.Integer, db.ForeignKey('roles.id' ))
将 User 模型中的 role_id 列定义为外键,来联接这两个表。传给 db.ForeignKey() 的参数 roles.id 声明,这列的值是 roles 表中相应行的 id值。
添加到 Role 模型中的 users 属性,代表整个关系的面向对象视角,对于一个 Role 类的实例,其 users 属性将返回与角色相关联的用户组成的列表。
db.relationship() 的第一个参数编码整个关系的另一端是哪个模型;backref 参数向 User 模型中添加一个 role 属性,从而定义反向关系。通过 User 实例的这个role属性可以获取对应的 Role 模型的对象
数情况下,db.relationship() 都能自行找到关系中的外键,但有时却无法确定哪一列是外键。
常用的 SQLAlchemy 关系选项:
选项名
说明
backref
在关系的另一个模型中添加反向引用
primaryjoin
明确指定两个模型之间使用的联结条件;只在模棱两可的关系中需要指定
lazy
指定如何加载相关记录,可选值有 select (首次访问时按需加载)、 immediate (源对象加载后就加载)、 joined(加载记录,但使用联结)、 subquery (立即加载,但使用子查询), noload (永不加载)和 dynamic (不加载记录,但提供加载记录的查询)
uselist
如果设为 False ,不使用列表,而使用标量值
order_by
指定关系中记录的排序方式
secondary
指定多对多关系中关联表的名称
secondaryjoin
SQLAlchemy 无法自行决定时,指定多对多关系中的二级联结条件
除了一对多关系之外:
一对一 关系可以用一对多关系表示,但调用 db.relationship() 时要把 uselist 设为 False ,把“多”变成“一”。
多对一 关系也可使用一对多表示,对调两个表即可,或者把外键和 db.relationship() 都放在“多”这一侧。
最复杂的关系类型是多对多 ,需要用到第三张表,这个表称为关联表(或联结表 )。
<br>
四、数据库操作 为了方便学习,我们先再Python shell中实际操作数据库模型,先将 FLASK_APP 环境变量设为 hellp.py,然后再虚拟环境终端中使用 flask shell 命令启动。
4.1 创建表 首先要让 Flask-SQLAlchemy 根据模型类创建数据库。 db.create_all() 函数将寻找所有 db.Model 的子类,然后再数据库中创建对应的表:
1 2 >>> from hello import db>>> db.create_all()
执行完上面命令后,在应用目录中就会产生一个 data.sqlite文件。
如果数据库表已经存在于数据库中,那么 db.create_all() 不会重新创建或者更新相应的表。使用 db.drop_all() 可以删除旧表,然后再重新创建,这样可以更新数据库,但是并不推荐,因为会丢失原有的数据。
4.2 插入行 (1)创建一些角色和用户如下:
1 2 3 4 5 6 7 >>> from hello import Role, User>>> admin_role = Role(name='Admin' )>>> mod_role = Role(name='Moderator' )>>> user_role = Role(name='User' )>>> user_john = User(username='john' , role=admin_role)>>> user_susan = User(username='susan' , role=user_role)>>> user_david = User(username='david' , role=user_role)
模型的构造函数接受的参数是使用关键字参数指定的模型属性初始值。
role 属性也可使用,虽然它不是真正的数据库列,但却是一对多关系的高级表示。
id 属性为主键,通常有数据库自身管理。而现在这些对象只存在于 Python 中,还未写入数据库,因此 id 并未赋值。
(2)对数据库的改动通过数据库会话(也称事务)管理,由 db.session 表示。准备把对象写入数据库之前,要先将其添加到会话中:
1 2 3 4 5 6 >>> db.session.add(admin_role) >>> db.session.add(mod_role) >>> db.session.add(user_role) >>> db.session.add(user_john) >>> db.session.add(user_susan) >>> db.session.add(user_david)
也可以简写成
1 >>> db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
(3)然后我们调用 commit() 方法提交会话,这样对象才被真正写入了数据库。
(4)数据库会话(事务)可以保证数据库的一致性。提交操作使用原子方式把会话中的对象全部写入数据库。如果在写入会话的过程中发生了错误,那么整个会话都会失效。如果你始终把相关改动放在会话中提交,就能避免因部分更新导致的数据库不一致。
数据库会话也可以调用 db.session.rollback() 进行回滚,回滚后添加到数据库会话中的所有对象都将还原到它们在数据库中的状态。
4.3 修改行 在数据库会话上调用 add() 方法也可以更新模型,如将 Admin 角色重命名未 Administrator:
1 2 3 4 5 >>> admin_role.name = 'Administrator' >>> db.session.add(admin_role) >>> db.session.commit()>>>> admin_role.name 'Administrator'
4.4 删除行 数据库会话可以用 delete() 方法来删除数据,如将 Moderator 角色从数据库中删除:
1 2 >>> db.session.delete(mod_role)>>> db.session.commit()
删除与插入和更新一样,只有提交数据库会话后才会执行。
4.5 查询行 (1)Flask-SQLAlchemy 为每个模型类都提供了 query 对象。最基本的模型查询是使用 all() 方法取回对应表中所有记录:
1 2 3 4 5 >>> Role.query.all ()[<Role 'Administrator' >, <Role 'User' >] >>> >>> User.query.all ()[<User 'john' >, <User 'susan' >, <User 'david' >]
使用过滤器可以配置 query 对象来进行更精准的数据库查询,如查找角色为 “User” 的所有用户:
1 2 >>> User.query.filter_by(role=user_role).all ()[<User 'susan' >, <User 'david' >]
若想查看 SQLAlchemy 为查询生成的原生SQL语句,可以将 query 对象转换为字符串:
1 2 >>> str (User.query.filter_by(role=user_role))'SELECT users.id AS users_id, users.username AS users_username, users.role_id AS users_role_id \nFROM users \nWHERE ? = users.role_id'
如果退出了当前 shell,再重新打开的化,前面例子创建的对象就不会以 Python 对象的方式存在,只能从数据库表中进行读取,重新创建Python对象。如下例发起一个查询,加载名为“User” 的用户角色:
1 user_role = Role.query.filter_by(name='User' ).first()
first() 方法只返回第一个结果,如果没有结果的化,返回None。
all() 方法以列表的形式返回查询到的所有结果。
(2)常用的 SQLAlchemy 查询过滤器:
过滤器
说明
filter()
把过滤器添加到原查询上,返回一个新查询
filter_by()
把等值过滤器添加到原查询上,返回一个新查询
limit()
使用指定的值限制原查询返回的结果数量,返回一个新查询
offset()
偏移原查询返回的结果,返回一个新查询
order_by()
根据指定条件对原查询结果进行排序,返回一个新查询
group_by()
根据指定条件对原查询结果进行分组,返回一个新查询
(3)常用的 SQLAlchemy 查询执行方法:
方法
说明
all()
以列表形式返回查询的所有结果
first()
返回查询的第一个结果,如果没有结果,则返回 None
first_or_404()
返回查询的第一个结果,如果没有结果,则终止请求,返回 404 错误响应
get()
返回指定主键对应的行,如果没有对应的行,则返回 None
get_or_404()
返回指定主键对应的行,如果没找到指定的主键,则终止请求,返回 404 错误响应
count()
返回查询结果的数量
paginate()
返回一个 Paginate 对象,包含指定范围内的结果
(4)关系与查询的处理方式类似,下面的例子首先查询角色为 User 的用户有哪些,然后又查询了用户susan的角色是什么,分别从关系的两端查询角色和用户之间的一对多关系。
1 2 3 4 5 >>> users = user_role.users>>> users[<User 'susan' >, <User 'david' >] >>> users[0 ].role<Role 'User' >
可以发现这里再执行 user_role.users时,隐式的调用了 all()方法,此时 query 对象被隐藏了,这样就无法再使用过滤器进行更精准的查询(如将结果按字母顺序排序)。
要想解决这个问题,我们需要在 Role 类的 db.relationship() 方法中加入 lazy='dynamic' 参数的设置,从而禁止自动执行查询。
1 2 3 4 class Role (db.Model): users = db.relationship('User' , backref='role' , lazy='dynamic' )
这样配置关系之后,user_role.users 将返回一个尚未执行的查询,因此可以在其上添加过滤器:
1 2 3 4 >>> user_role.users.order_by(User.username).all ()[<User 'david' >, <User 'susan' >] >>> user_role.users.count()2
<br>
五、在视图函数中操作数据库 实际上,上面介绍一系列数据库操作可以直接在视图函数中进行,如下例hello.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 from flask import Flask, render_template, session, redirect, url_for, flashfrom flask_bootstrap import Bootstrapfrom flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredfrom flask_moment import Momentimport osfrom flask_sqlalchemy import SQLAlchemybasedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SECRET_KEY' ] = 'I am Lethe' app.config['SQLALCHEMY_DATABASE_URI' ] = 'sqlite:///' + \ os.path.join(basedir, 'data.sqlite' ) app.config['SQLALCHEMY_TRACK_MODIFICATIONS' ] = False db = SQLAlchemy(app) bootstrap = Bootstrap(app) moment = Moment(app) class NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' ) class Role (db.Model): __tablename__ = 'roles' id = db.Column(db.Integer, primary_key=True ) name = db.Column(db.String(64 ), unique=True ) users = db.relationship('User' , backref='role' ) def __repr__ (self ): return '<Role %r>' % self.name class User (db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True ) username = db.Column(db.String(64 ), unique=True , index=True ) role_id = db.Column(db.Integer, db.ForeignKey('roles.id' )) def __repr__ (self ): return '<User %r>' % self.username @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): user = User.query.filter_by(username=form.name.data).first() if user is None : user = User(username=form.name.data) db.session.add(user) db.session.commit() session['known' ] = False else : session['known' ] = True session['name' ] = form.name.data form.name.data = '' return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ), known=session.get('known' , False ))
这个例子在提交表单后,会先查询数据库来判断该用户是否存在,若不存在,则添加该新用户,且session['known']为False,若存在,则session['known']为True。
然后我们可以将 known 传给模板,模板可以根据是否为老用户来生成不同的消息,如下templates/index.html:
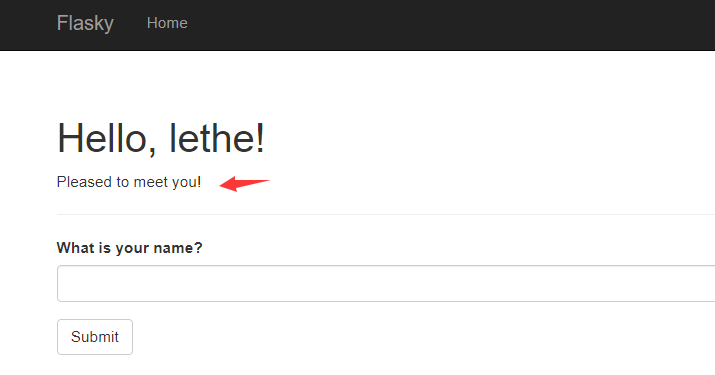
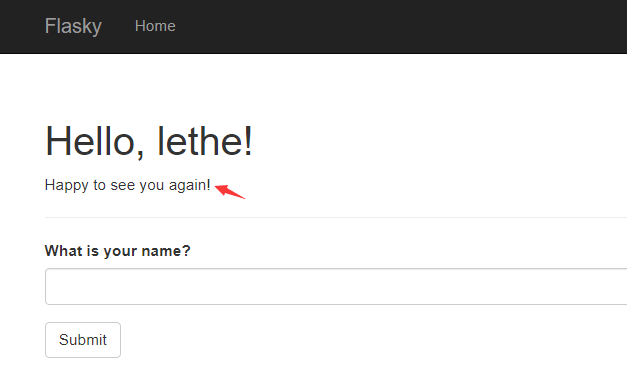
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 {% extends "base.html" %} {% import "bootstrap/wtf.html" as wtf %} {% block title %}Flasky{% endblock %} {% block page_content %} <div class ="page-header" > <h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1> {% if not known %} <p>Pleased to meet you!</p> {% else %} <p>Happy to see you again!</p> {% endif %} </div> {{ wtf.quick_form(form) }} {% endblock %}
第一次提交:
再次提交:
<br>
六、集成Python shell 每次启动 shell 会话都要导入数据库实例和模型,为了避免一直重复导入,可以做些配置让 flask shell 命令自动导入这些对象。
若想把对象添加到导入列表中,必须使用 app.shell_context_processor 装饰器创建并注册一个 shell 上下文处理器如下:
1 2 3 @app.shell_context_processor def make_shell_context (): return dict (db=db, User=User, Role=Role)
这个 shell 上下文处理器函数返回一个字典,包含数据库实例和模型。除了默认导入的 app 之外,flask shell 命令将自动把这些对象导入shell。
1 2 3 4 5 6 7 8 9 10 >>> app<Flask 'hello' > >>> db<SQLAlchemy engine=sqlite:///F:\MyCode\Python\FlaskWebLearn\flasky\data.sqlite> >>> User<class 'hello.User' > >>> Role<class 'hello.Role' > >>> Role.query.all ()[<Role 'Administrator' >, <Role 'User' >]
<br>
七、使用Flask-Migrate实现数据库迁移 有时需要修改数据库模型,而且修改之后还要更新数据库,但是前面说了当数据库表已经存在的时候,不会再创建模型了,只能删掉旧表后再重新创建,这样显然不好。
因此更好的方法就是使用数据库迁移框架 ,数据库迁移框架能跟踪数据库模式 的变化,然后以增量的方式把变化应用到数据库中。
SQLAlchemy 的开发人员编写了一个迁移框架,名为 Alembic。除了直接使用 Alembic 之外,Flask 应用还可使用 Flask-Migrate 扩展。这个扩展是对 Alembic 的轻量级包装,并与 flask 命令做了集成。首先在虚拟环境中安装此扩展:
1 pip install flask-migrate
7.1 创建迁移仓库 此扩展在使用前同样需要先初始化:
1 2 3 from flask_migrate import Migratemigrate = Migrate(app, db)
为了开放数据库迁移相关的命令,Flask-Migrate 添加了 flask db 命令和几个子命令。在新项目中可以使用 init 子命令添加数据库迁移支持,这个命令会创建 migrations 目录,所有迁移脚本都存放在这里。
1 2 3 4 5 6 7 8 (venv) PS F:\MyCode\Python\FlaskWebLearn\flasky> flask db init Creating directory F:\MyCode\Python\FlaskWebLearn\flasky\migrations ... done Creating directory F:\MyCode\Python\FlaskWebLearn\flasky\migrations\versions ... done Generating F:\MyCode\Python\FlaskWebLearn\flasky\migrations\alembic.ini ... done Generating F:\MyCode\Python\FlaskWebLearn\flasky\migrations\env.py ... done Generating F:\MyCode\Python\FlaskWebLearn\flasky\migrations\README ... done Generating F:\MyCode\Python\FlaskWebLearn\flasky\migrations\script.py.mako ... done Please edit configuration/connection/logging settings in 'F:\\MyCode\\Python\\FlaskWebLearn\\flasky\\migrations\\alembic.ini' before proceeding.
7.2 创建迁移脚本 (1)在 Alembic 中,数据库迁移用迁移脚本表示,迁移脚本有两个函数,分别是upgrade() 和 downgrade() 。
upgrade() 函数把迁移中的改动应用到数据库中
downgrade() 函数则将改动删除
我们可以使用 revision 命令手动创建 Alembic 迁移,也可使用migrate 命令自动创建。
手动创建的迁移只是一个骨架,upgrade() 和 downgrade() 函数都是空的,开发者要使用 Alembic 提供的Operations 对象指令实现具体操作。
自动创建的迁移会根据模型定义和数据库当前状态之间的差异尝试生成 upgrade() 和 downgrade() 函数的内容。
自动创建的迁移不一定总是正确的,可能会漏掉一些细节,因此自动生成迁移脚本后一定要进行检查。
(2)使用 Flask-Migrate 管理数据库模式变化的步骤如下:flask db migrate 命令,自动创建一个迁移脚本。flask db upgrade 命令,把迁移应用到数据库中。
例如我们想在 User 表中加入一列 message,先在 User 类中加入 message 属性:
1 2 3 4 class User (db.Model): message = db.Column(db.Text)
然后使用 flask db migrate 命令自动创建迁移脚本:
1 2 3 4 5 (venv) PS F:\MyCode\Python\FlaskWebLearn\flasky> flask db migrate -m "initial migration" INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added column 'users.message' Generating F:\MyCode\Python\FlaskWebLearn\flasky\migrations\versions\2ad03fb29744_initial_migration.py ... done
7.3 更新数据库 (1)检查并修正好迁移脚本之后,执行 flask db upgrade 命令,把迁移应用到数据库中:
1 2 3 4 (venv) PS F:\MyCode\Python\FlaskWebLearn\flasky> flask db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade -> 2ad03fb29744, initial migration
(2)这时User表中已经增加了一列message,然后启动 flask shell,分别为 admin和 Lethe 用户添加 message 数据表示各自的定制消息:
1 2 3 4 5 6 7 >>> admin_user = User.query.filter_by(username='admin' ).first()>>> lethe_user = User.query.filter_by(username='Lethe' ).first() >>> admin_user.message = 'You are the admin, you can do anything!' >>> lethe_user.message = 'Hello Lethe, Welcome Back!' >>> db.session.add(admin_user)>>> db.session.add(lethe_user)>>> db.session.commit()
(3)然后修改hello.py 中的视图函数,使其能够为 admin 和 Lethe 用户显示各自定制的消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from flask import Flask, render_template, session, redirect, url_for, flashfrom flask_bootstrap import Bootstrapfrom flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredfrom flask_moment import Momentimport osfrom flask_sqlalchemy import SQLAlchemyfrom flask_migrate import Migratebasedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SECRET_KEY' ] = 'I am Lethe' app.config['SQLALCHEMY_DATABASE_URI' ] = 'sqlite:///' + \ os.path.join(basedir, 'data.sqlite' ) app.config['SQLALCHEMY_TRACK_MODIFICATIONS' ] = False bootstrap = Bootstrap(app) moment = Moment(app) db = SQLAlchemy(app) migrate = Migrate(app, db) class NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' ) class Role (db.Model): __tablename__ = 'roles' id = db.Column(db.Integer, primary_key=True ) name = db.Column(db.String(64 ), unique=True ) users = db.relationship('User' , backref='role' ) def __repr__ (self ): return '<Role %r>' % self.name class User (db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True ) username = db.Column(db.String(64 ), unique=True , index=True ) role_id = db.Column(db.Integer, db.ForeignKey('roles.id' )) message = db.Column(db.Text) def __repr__ (self ): return '<User %r>' % self.username @app.shell_context_processor def make_shell_context (): return dict (db=db, User=User, Role=Role) @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): user = User.query.filter_by(username=form.name.data).first() if user is None : user = User(username=form.name.data) db.session.add(user) db.session.commit() session['known' ] = False else : session['known' ] = True session['name' ] = form.name.data session['message' ] = user.message form.name.data = '' return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ), known=session.get('known' , False ), message=session.get('message' ))
(4)再修该一下tempates/index.html,使其能够显示定制消息:
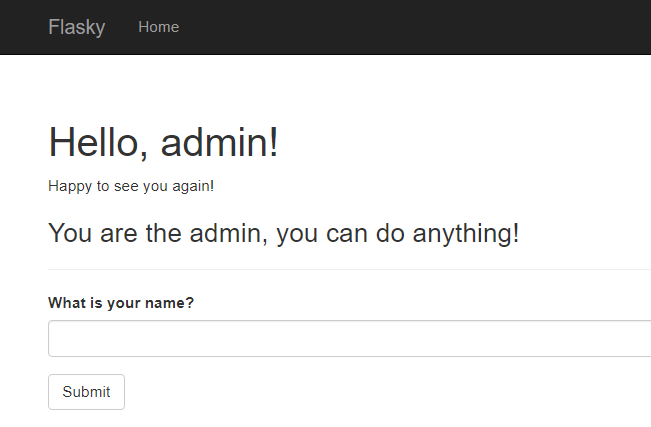
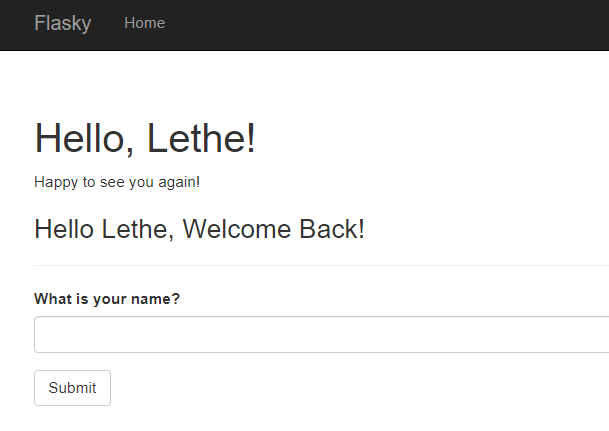
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 {% extends "base.html" %} {% import "bootstrap/wtf.html" as wtf %} {% block title %}Flasky{% endblock %} {% block page_content %} < div class="page-header"> < h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!< /h1> {% if not known %} < p>Pleased to meet you!< /p> {% else %} < p>Happy to see you again!< /p> {% endif %} {% if message %} < h3>{{ message }}< /h3> {% endif %} < /div>{{ wtf.quick_form(form) }} {% endblock %}
(5)效果如下:
① admin用户
7.4 添加几个迁移 (1)在开发项目的过程中,时常要修改数据库模型。如果使用迁移框架管理数据库,必须在迁移脚本中定义所有改动,否则改动将不可复现。
修改数据库 的步骤与创建第一个迁移类似:flask db migrate 命令,生成迁移脚本。flask db upgrade 命令,把改动应用到数据库中。
(2)实现一个功能时,可能要多次修改数据库模型才能得到预期结果。如果前一个迁移还未提交到源码控制系统中,可以继续在那个迁移中修改,以免创建大量无意义的小迁移脚本。
在前一个迁移脚本的基础上修改的步骤如下:flask db downgrade 命令,还原前一个脚本对数据库的改动(注意,这可能导致部分数据丢失)。flask db migrate 命令生成一个新的数据库迁移脚本。这个迁移脚本除了前面删除的那个脚本中的改动之外,还包括这一次对模型的改动。
与数据库迁移相关的其他子命令参见 Flask-Migrate 文档(https://flask-migrate.readthedocs.io/ )
<br>
0x05 电子邮件 在 Python 标准库中通常使用 smtplib 包发送电子邮件,而 Flask 中的 Flask-Mail 扩展不仅包装了 smtplib,且能更好的与 Flask 集成。首先在虚拟环境中安装此扩展:
Flask-Mail文档:http://www.pythondoc.com/flask-mail/index.html
一、配置 Flask-Mail 连接到简单邮件传输协议(SMTP,simple mail transferprotocol)服务器,把邮件交给这个服务器发送。如果不进行配置,则 Flask-Mail 连接 localhost 上的 25 端口,无须验证身份即可发送电子邮件。
Flask-Mail SMTP 服务器配置:
配置
默认值
说明
MAIL_SERVER
localhost
电子邮件服务器的主机名或 IP 地址
MAIL_PORT
25
电子邮件服务器的端口
MAIL_USE_TLS
False
启用传输层安全(TLS,transport layer security)协议
MAIL_USE_SSL
False
启用安全套接层(SSL,secure sockets layer)协议
MAIL_USERNAME
None
邮件账户的用户名
MAIL_PASSWORD
None
邮件账户的密码
实际中,连接到外部 SMTP 服务器更方便,如下例使用 qq邮箱的配置:
1 2 3 4 5 6 7 import osapp.config['MAIL_SERVER' ] = 'smtp.qq.com' app.config['MAIL_PORT' ] = 465 app.config['MAIL_USE_SSL' ] = True app.config['MAIL_USERNAME' ] = os.environ.get('MAIL_USERNAME' ) app.config['MAIL_PASSWORD' ] = os.environ.get('MAIL_PASSWORD' )
注意qq邮箱需要先开启SMTP服务,并得到授权码:
由于QQ邮箱不支持非加密的协议,那么使用加密协议,分为两种加密协议,选择其中之一即可
MAIL_USE_TLS:端口号是587
MAIL_USE_SSL:端口号是465
Flask-Mail在使用前也需要进行初始化:
1 2 from flask_mail import Mailmail = Mail(app)
保存电子邮件服务器用户名和密码的两个环境变量要在环境中定义。如果你使用的是 Linux 或 macOS,可以按照下面的方式设定这两个变量:
1 2 export MAIL_USERNAME=<mail username>export MAIL_PASSWORD=<mail password>
微软 Windows 用户可按照下面的方式设定环境变量:
1 2 3 4 5 6 7 set MAIL_USERNAME=<mail username>set MAIL_PASSWORD=<mail password>$env :MAIL_USERNAME='<mail username>' $env :MAIL_PASSWORD='<mail password>'
<br>
二、在Python shell中发送电子邮件 打开一个 shell 会话(powershell),来发送一个测试邮件。
先配置一下环境变量,上面的方式定义的是临时环境变量,每个新shell都需要导入一次。
1 2 3 $env :FLASK_APP='.\hello.py' $env :MAIL_USERNAME='your_email@qq.com' $env :MAIL_PASSWORD='你的授权码'
然后打开 flask shell 进行测试:
1 2 3 4 5 6 7 >>> from flask_mail import Message >>> from hello import mail >>> msg = Message('test email' , sender='your_email@qq.com' , recipients=['your_email@qq.com' ]) >>> msg.body = 'This is the plain text body' >>> msg.html = 'This is the <b>HTML</b> body' >>> with app.app_context(): ... mail.send(msg)
注意:Flask-Mail 的 send() 函数使用 current_app ,因此要在激活的应用上下文中执行。
成功收到邮件:
<br>
三、在应用中集成邮件发送功能 一般把发送电子邮件的部分定义为一个函数,这样还可以使用 Jinja2 模板渲染邮件正文,灵活性高。
1 2 3 4 5 6 7 8 9 10 11 12 13 from flask_mail import Messageapp.config['FLASKY_MAIL_SUBJECT_PREFIX' ] = '[Flasky]' app.config['FLASKY_MAIL_SENDER' ] = 'Flasky Admin <xxxx@qq.com>' def sned_email (to, subject, template, **kwargs ): msg = Message(app.config['FLASKY_MAIL_SUBJECT_PREFIX' ] + subject, sender=app.config['FLASKY_MAIL_SENDER' ], recipients=[to]) msg.body = render_template(template + '.txt' , **kwargs) msg.html = render_template(template + '.html' , **kwargs) mail.send(msg)
send_mail() 函数的参数分别为收件人地址(to)、主题(subject)、渲染邮件正文的模板(template)、关键字参数列表(**kwargs)。
指定模板时不包含扩展名,这样才能使用两个模板分别渲染txt和HTML。
调用者传入
下面我们修改视图函数 index(),使表单每接收到新的名字,应用就给管理员发送一封电子邮件,修改hello.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 app.config['FLASKY_ADMIN' ] = os.environ.get('FLASKY_ADMIN' ) @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): user = User.query.filter_by(username=form.name.data).first() if user is None : user = User(username=form.name.data) db.session.add(user) db.session.commit() session['known' ] = False if app.config['FLASKY_ADMIN' ]: sned_email(app.config['FLASKY_ADMIN' ], 'New User' , 'mail/new_user' , user=user) else : session['known' ] = True session['name' ] = form.name.data session['message' ] = user.message form.name.data = '' return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ), known=session.get('known' , False ), message=session.get('message' ))
templates/mai/new_user.txt:
1 User {{ user.username }} has joined.
templates/mai/new_user.html:
1 User < b>{{ user.username }}< /b> has joined.
电子邮件的收件人地址保存在环境变量 FLASKY_ADMIN 中,启动前需要导入此环境变量,方法和前面的相同。
我们还需要创建两个模板文件,分别用于渲染纯文本和HTML版本的邮件正文。这两个模板文件都保存在 templates 目录下的 mail 子目录中。
电子邮件的模板中有一个模板参数是用户,因此调用 send_email() 函数时要以关键字参数的形式传入用户。
现在每次你在表单中填写新名字(如email test),管理员(FLASKY_ADMIN)都会收到一封电子邮件。
<br>
四、异步发送电子邮件 在上面的例子中,我们发现在发送电子邮件的时候,网页会停滞一会,为了避免用户感觉到这样的延迟,可以把发送电子邮件的函数移到后台线程中,修改方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from threading import Threaddef send_async_email (app, msg ): with app.app_context(): mail.send(msg) def sned_email (to, subject, template, **kwargs ): msg = Message(app.config['FLASKY_MAIL_SUBJECT_PREFIX' ] + subject, sender=app.config['FLASKY_MAIL_SENDER' ], recipients=[to]) msg.body = render_template(template + '.txt' , **kwargs) msg.html = render_template(template + '.html' , **kwargs) thr = Thread(target=send_async_email, args=[app, msg]) thr.start() return thr
很多 Flask 扩展都假设已经存在激活的应用上下文和(或)请求上下文。Flask-Mail 的 send() 函数使用 current_app ,因此必须激活应用上下文。
不过,上下文是与线程配套的,在不同的线程中执行 mail.send() 函数时,要使用 app.app_context() 人工创建应用上下文。app 实例作为参数传入线程,因此可以通过它来创建上下文。
<br>
0x06 重构应用结构 到现在为止,hello.py的完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 from flask import Flask, render_template, session, redirect, url_for, flashfrom flask_bootstrap import Bootstrapfrom flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredfrom flask_moment import Momentimport osfrom flask_sqlalchemy import SQLAlchemyfrom flask_migrate import Migratefrom flask_mail import Mailfrom flask_mail import Messagefrom threading import Threadbasedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SECRET_KEY' ] = 'I am Lethe' app.config['SQLALCHEMY_DATABASE_URI' ] = 'sqlite:///' + \ os.path.join(basedir, 'data.sqlite' ) app.config['SQLALCHEMY_TRACK_MODIFICATIONS' ] = False app.config['MAIL_SERVER' ] = 'smtp.qq.com' app.config['MAIL_PORT' ] = 465 app.config['MAIL_USE_SSL' ] = True app.config['MAIL_USERNAME' ] = os.environ.get('MAIL_USERNAME' ) app.config['MAIL_PASSWORD' ] = os.environ.get('MAIL_PASSWORD' ) app.config['FLASKY_MAIL_SUBJECT_PREFIX' ] = '[Flasky]' app.config['FLASKY_MAIL_SENDER' ] = 'Flasky Admin <xxxxxxx@qq.com>' app.config['FLASKY_ADMIN' ] = os.environ.get('FLASKY_ADMIN' ) bootstrap = Bootstrap(app) moment = Moment(app) db = SQLAlchemy(app) migrate = Migrate(app, db) mail = Mail(app) class NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' ) class Role (db.Model): __tablename__ = 'roles' id = db.Column(db.Integer, primary_key=True ) name = db.Column(db.String(64 ), unique=True ) users = db.relationship('User' , backref='role' ) def __repr__ (self ): return '<Role %r>' % self.name class User (db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True ) username = db.Column(db.String(64 ), unique=True , index=True ) role_id = db.Column(db.Integer, db.ForeignKey('roles.id' )) message = db.Column(db.Text) def __repr__ (self ): return '<User %r>' % self.username @app.shell_context_processor def make_shell_context (): return dict (db=db, User=User, Role=Role) def send_async_email (app, msg ): with app.app_context(): mail.send(msg) def sned_email (to, subject, template, **kwargs ): msg = Message(app.config['FLASKY_MAIL_SUBJECT_PREFIX' ] + subject, sender=app.config['FLASKY_MAIL_SENDER' ], recipients=[to]) msg.body = render_template(template + '.txt' , **kwargs) msg.html = render_template(template + '.html' , **kwargs) thr = Thread(target=send_async_email, args=[app, msg]) thr.start() return thr @app.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): user = User.query.filter_by(username=form.name.data).first() if user is None : user = User(username=form.name.data) db.session.add(user) db.session.commit() session['known' ] = False if app.config['FLASKY_ADMIN' ]: sned_email(app.config['FLASKY_ADMIN' ], 'New User' , 'mail/new_user' , user=user) else : session['known' ] = True session['name' ] = form.name.data session['message' ] = user.message form.name.data = '' return redirect(url_for('index' )) return render_template('index.html' , form=form, name=session.get('name' ), known=session.get('known' , False ), message=session.get('message' )) @app.route('/user/<name>' def user (name ): return render_template('user.html' , name=name) @app.errorhandler(404 def pate_not_found (e ): return render_template('404.html' ), 404 @app.errorhandler(500 def internal_server_error (e ): return render_template('500.html' ), 500
可以看到随着应用复杂程度增加,将所有部分写在一个脚本里会导致许多问题,而不同于多数其他的 Web 框架,Flask 并不强制要求大型项目使用特定的组织方式,应用结构的组织方式完全由开发者决定。
一、项目结构 多文件 Flask 应用的基本结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |-flasky |-app/ |-templates/ |-static/ |-main/ |-__init__.py |-errors.py |-forms.py |-views.py |-__init__.py |-email.py |-models.py |-migrations/ |-tests/ |-__init__.py |-test*.py |-venv/ |-requirements.txt |-config.py |-flasky.py
这种结构有4个顶级文件夹:
Flask 应用一般保存在名为 app 的包中;
数据库迁移脚本在 migrations 文件夹中;
单元测试在 tests 包中编写;
Python虚拟环境在 venv 文件夹中。
此外,还多了一些新文件:
requirements.txt 列出了所有依赖包,便于在其他计算机中重新生成相同的虚拟环境;
config.py 存储配置;
flasky.py 定义 Flask 应用实例,同时还有一些辅助管理应用的任务。
下面我们尝试把之前的 hello.py 应用转换成此种结构。
<br>
二、配置选项 应用经常需要设定多个配置,如开发、测试和生产环境要使用不同的数据库,这样才不会彼此影响。
除了 hello.py 中类似字典的 app.config 对象之外,还可以使用具有层次结构的配置类。将 hello.py 中的配置项独立在 config.py 中如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import osbasedir = os.path.abspath(os.path.dirname(__file__)) class Config : SECRET_KEY = os.environ.get('SECRET_KEY' ) or 'I am Lethe' MAIL_SERVER = os.environ.get('MAIL_SERVER' , 'smtp.qq.com' ) MAIL_PORT = int (os.environ.get('MAIL_PORT' , '465' )) MAIL_USE_TLS = os.environ.get('MAIL_USE_SSL' , 'true' ).lower() in \ ['true' , 'on' , '1' ] MAIL_USERNAME = os.environ.get('MAIL_USERNAME' ) MAIL_PASSWORD = os.environ.get('MAIL_PASSWORD' ) FLASKY_MAIL_SUBJECT_PREFIX = '[Flasky]' FLASKY_MAIL_SENDER = 'Flasky Admin <xxxxxxx@qq.com>' FLASKY_ADMIN = os.environ.get('FLASKY_ADMIN' ) sQLALCHEMY_TRACK_MODIFICATIONS = False @staticmethod def init_app (app ): pass class DevelopmentConfig (Config ): DEBUG = True SQLALCHEMY_DATABASE_URI = os.environ.get('DEV_DATABASE_URL' ) or \ 'sqlite:///' + os.path.join(basedir, 'data-dev.sqlite' ) class TestingConfig (Config ): TESTING = True SQLALCHEMY_DATABASE_URI = os.environ.get('TEST_DATABASE_URL' ) or \ 'sqlite://' class ProductionConfig (Config ): SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL' ) or \ 'sqlite:///' + os.path.join(basedir, 'data.sqlite' ) config = { 'development' : DevelopmentConfig, 'testing' : TestingConfig, 'production' : ProductionConfig, 'default' : DevelopmentConfig }
基本Config包含通用配置,各个子类分别定义专用的配置。如果需要,也可以添加其他配置类。
为了更安全和灵活,多数配置都可以从环境变量中导入。
在 3 个子类中,SQLALCHEMY_DATABASE_URI 变量都被指定了不同的值。这样应用就可以在不同的环境中使用不同的数据库。
开发环境和生产环境都配置了邮件服务器。为了再给应用提供一种定制配置的方式,Config 类及其子类可以定义 init_app() 类方法,其参数为应用实例。现在,基类 Config 中的 init_app() 方法为空。
在这个配置脚本末尾,config 字典中注册了不同的配置环境,而且还注册了一个默认配置(这里注册为开发环境)。
<br>
三、应用包 应用包用来存放应用的所有代码、模板和静态文件,通常称为为 app(应用)。templates 和 static 目录需要移动到应用包中,数据库模型和电子邮件支持函数也要移到这个包中,分别保存为 app/models.py 和 app/email.py。
3.1 使用应用工厂函数 单个文件中开发应用是很方便,但却有个很大的缺点:应用在全局作用域中创建,无法动态修改配置。运行脚本时,应用实例已经创建,再修改配置为时已晚。这一点对单元测试尤其重要,因为有时为了提高测试覆盖度,必须在不同的配置下运行应用。
这个问题的解决方法是延迟创建应用实例,把创建过程移到可显式调用的工厂函数中。这种方法不仅可以给脚本留出配置应用的时间,还能够创建多个应用实例,为测试提供便利。
应用的工厂函数在 app 包的构造文件 app/__init__.py 中定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from flask import Flask, render_templatefrom flask_bootstrap import Bootstrapfrom flask_mail import Mailfrom flask_moment import Momentfrom flask_sqlalchemy import SQLAlchemyfrom config import configbootstrap = Bootstrap() mail = Mail() moment = Moment() db = SQLAlchemy() def create_app (config_name ): app = Flask(__name__) app.config.from_object(config[config_name]) config[config_name].init_app(app) bootstrap.init_app(app) mail.init_app(app) moment.init_app(app) db.init_app(app) from .main import main as main_blueprint app.register_blueprint(main_blueprint) return app
构造文件导入了大多数使用的 Flask 扩展,由于此时尚未初始化应用实例,所以这些扩展的实例化并未传参,也就没有真正初始化。
create_app() 函数是应用的工厂函数,接收一个参数,即应用使用的配置名(前面在config.py中定义的)。配置可以通过 app.config 配置对象提供的 from_object() 方法直接导入应用,参数 config[config_name] 即从 config 字典中选择一个配置类进行配置。
在之前创建的的扩展对象上调用 init_app() 方法可以将 Flask 扩展完成初始化。
3.2 在蓝本中实现应用功能 (1)蓝本(blueprint)和应用类似,也可以定义路由和错误处理程序。但是在蓝本中定义的路由和错误处理程序处于休眠状态,直到蓝本注册到应用上之后,才相当于真正定义在了应用中。
蓝本可以在单个文件中定义,也可使用更结构化的方式在
此子包的构造文件 app/main/__init__.py 如下,创建主蓝本:
1 2 3 4 5 from flask import Blueprintmain = Blueprint('main' , __name__) from . import views, errors
蓝本通过实例化一个 Blueprint 类对象创建。这个构造函数有两个必须指定的参数:蓝本的名称和蓝本所在的包或模块。
应用的路由保存在包里的 app/main/views.py 模块中,而错误处理程序保存在 app/main/errors.py 模块中,导入这两个模块就能把路由和错误处理程序与蓝本关联起来。
这些模块在 app/main/init .py 脚本的末尾导入,这是为了避免循环导入依赖,因为在 app/main/views.py 和app/main/errors.py 中还要导入 main 蓝本,所以除非循环引用出现在定义 main 之后,否则会致使导入出错。
(2)蓝本在工厂函数 create_app() 中注册到应用上,如下注册主蓝本:
1 2 3 4 5 6 7 def create_app (config_name ):from .main import main as main_blueprintapp.register_blueprint(main_blueprint) return app
(3)主蓝本中的错误处理程序 app/main/errors.py:
1 2 3 4 5 6 7 8 9 10 11 from flask import render_templatefrom . import main@main.app_errorhandler(404 def pate_not_found (e ): return render_template('404.html' ), 404 @main.app_errorhandler(500 def internal_server_error (e ): return render_template('500.html' ), 500
之前我们使用的是 errorhandler 装饰器,但是在蓝本中如果使用他,就只有蓝本中的错误才能触发处理程序。
因此我们需要使用 app_errorhandler 装饰器来注册全局的错误处理程序。
(4)主蓝本中定义的应用路由 app/main/views.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from datetime import datetimefrom flask import render_template, session, redirect, url_for, flashfrom . import mainfrom .forms import NameFormfrom .. import dbfrom ..models import User@main.route('/' , methods=['GET' , 'POST' ] def index (): form = NameForm() if form.validate_on_submit(): user = User.query.filter_by(username=form.name.data).first() if user is None : user = User(username=form.name.data) db.session.add(user) db.session.commit() session['known' ] = False if app.config['FLASKY_ADMIN' ]: sned_email(app.config['FLASKY_ADMIN' ], 'New User' , 'mail/new_user' , user=user) else : session['known' ] = True session['name' ] = form.name.data session['message' ] = user.message form.name.data = '' return redirect(url_for('main.index' )) return render_template('index.html' , form=form, name=session.get('name' ), known=session.get('known' , False ), message=session.get('message' )) @main.route('/user/<name>' def user (name ): return render_template('user.html' , name=name)
和错误处理程序一样,这里的路由装饰器使用的是 main.route,而不是 app.route。
url_for() 函数使用的是 url_for(‘main.index’) ,而不是 url_for(‘index’)。这是因为 Flask 会为蓝本中的全部端点加上一个命名空间,即为蓝本的名称(Blueprint 构造函数的第一个参数)。
若请求的端在在蓝本内,则也可以缩写为 url_for(‘.index’)
(5)还需要将表单类移到蓝本中,保存在 app/main/forms.py 模块中:
1 2 3 4 5 6 7 from flask_wtf import FlaskFormfrom wtforms import StringField, SubmitFieldfrom wtforms.validators import DataRequiredclass NameForm (FlaskForm ): name = StringField('What is your name?' , validators=[DataRequired()]) submit = SubmitField('Submit' )
<br>
四、应用脚本 应用实例在顶级目录中的 flasky.py 模块里定义:
1 2 3 4 5 6 7 8 9 10 11 import osfrom app import create_app, dbfrom app.models import User, Rolefrom flask_migrate import Migrateapp = create_app(os.getenv('FLASK_CONFIG' ) or 'default' ) migrate = Migrate(app, db) @app.shell_context_processor def make_shell_context (): return dict (db=db, User=User, Role=Role)
此主脚本先创建了一个应用实例,配置名可以从环境变量中读取,也可以使用默认值。
然后初始化数据库迁移扩展 Flask-Migreate 并为 Python shell 注册上下文。
现在我们要想运行应用,就需要把环境变量 FLASK_APP 设置为 flasky.py ,再执行 flask run 才可以。此外,还可以将 FLASK_DEBUG设置为1,来开启调试模式。
<br>
五、需求文件 应用中最好有个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号,以便在另一个环境上重新生成虚拟环境。
在虚拟环境中执行如下命令:
1 pip freeze >requirements.txt
在安装或升级包后,最好更新一下这个文件。
然后当你想创建这个虚拟环境的副本时,则可以先创建一个新的虚拟环境,然后根据 requirements.txt 安装需要的包和扩展:
1 pip install -r requirements.txt
<br>
六、创建数据库 首选从环境变量中读取数据库的 URL,同时还提供了一个默认的SQLite 数据库作为备用。3 种配置环境中的环境变量名和 SQLite 数据库文件名都不一样。
不管从哪里获取数据库 URL,都要在新数据库中创建数据表,参见“数据库”章节
如果使用 Flask-Migrate 跟踪迁移,可使用下述命令创建数据表或者升级到最新修订版本: