【这学期计算机视觉课程的结课作业中可选的最简单的一个题目,最终虽然没啥新东西,但是意外的性能好像还可以】
本次实验达到了Fer2013原始数据集单模型(不使用额外训练数据)的SOTA准确率 73.70%,代码已上传至GitHub:https://github.com/LetheSec/Fer2013-Recognition-Pytorch
1 介绍
表情识别是计算机理解人类情感的一个重要方向,也是人机交互的一个重要方面。表情识别是指从静态照片或视频序列中选择出表情状态,从而确定对人物的情绪与心理变化。20世纪70年代的美国心理学家Ekman和Friesen通过大量实验,定义了人类六种基本表情:快乐,气愤,惊讶,害怕,厌恶和悲伤,除此之外后续的分类任务大多增添了一个中性表情。人脸表情识别(FER)在人机交互和情感计算中有着广泛的研究前景,包括人机交互、情绪分析、智能安全等。
本次实验的使用的数据集为Fer2013,它于2013年国际机器学习会议(ICML)上推出,并成为比较表情识别模型性能的基准之一,同时也作为了2013年Kaggle人脸识别比赛的数据。Fer2013包含28709张训练集图像、3589张公开测试集图像和3589张私有测试集图像,每张图像为4848大小的灰度图片,如下图所示。Fer2013数据集中由有生气(angry)、厌恶(disgust)、恐惧(fear)、开心(happy)、难过(sad)、惊讶(surprise)和中性(neutral)七个类别组成。由于这个数据集大多是通过爬虫在互联网上进行爬取所得,因此存在一定的误差性,人类在该数据集上的准确率为 。

而在本次的实验提供的数据集是经过重新划分的,其中训练集只有17591张图像,比原始数据集少了近40%,而验证集和测试集数量则大幅增加,因此理论上在课程数据集上的性能会低于在原始数据集上的性能。
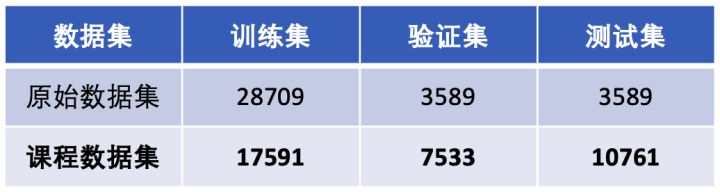
除此之外,该数据集七个类别样本数量并不是想等的,其中disgust类别的数量最少,happy类别样本数量最多。
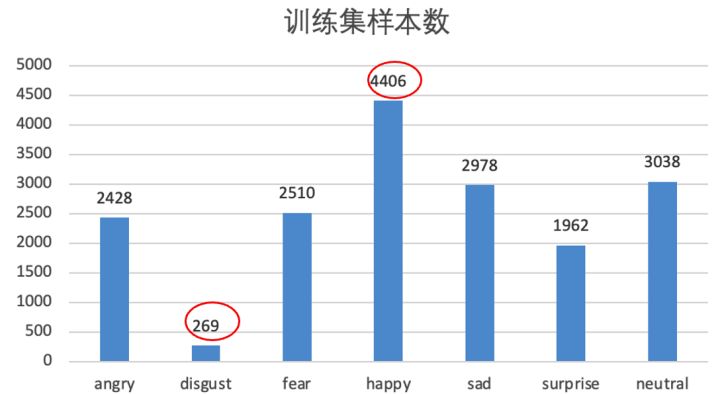
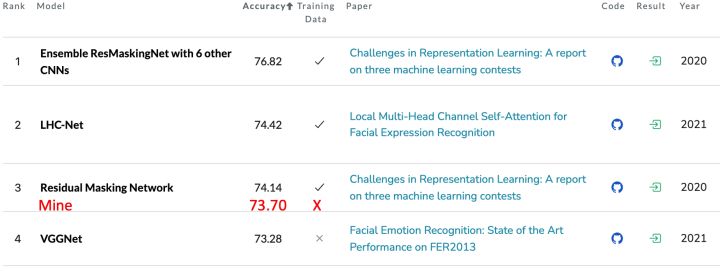
2 基准
为了后续实验有一个评价的基准,首先需要寻找目前Fer2013表情识别认为的Baseline方法。Papers With Code网站[1]收集了AI领域各个方向的论文对应代码,并形成了许多的benchmark排行榜用于研究者进行比较,并及时跟进最新的进展情况,该网站的Fer2013数据集排行榜如下图所示。
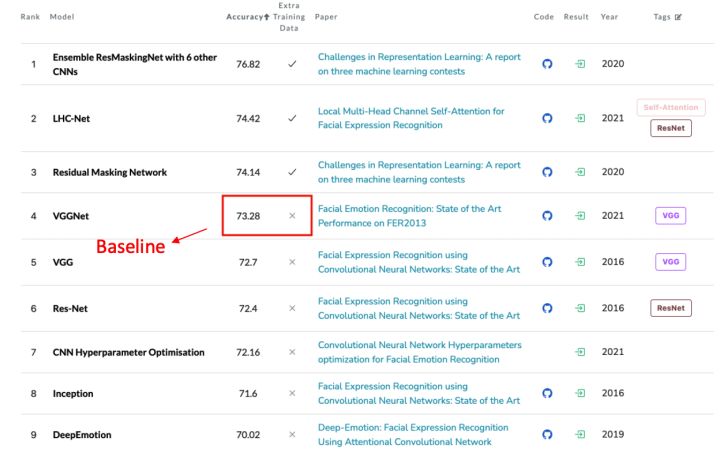
其中,前三名在Fer2013数据集之外还使用了额外的数据参与训练,与本次实验的目标不符,因此第四名[2]VGGNet所达到的73.28%即为单模型在Fer2013数据集上不使用额外训练数据时的表分类SOTA,我将该方法作为本次试验的Baseline。该方法基于VGG提出了一个变种的网络,并通过尝试不同的数据增强策略、学习率策略、优化器的选择,以及大量的参数调整,最终达到了单模型的SOTA性能。
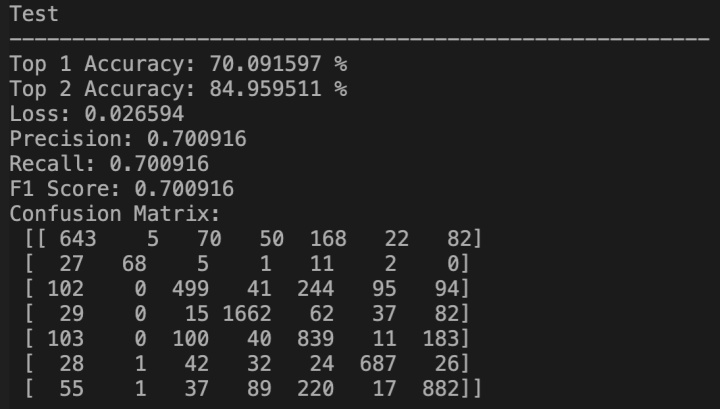
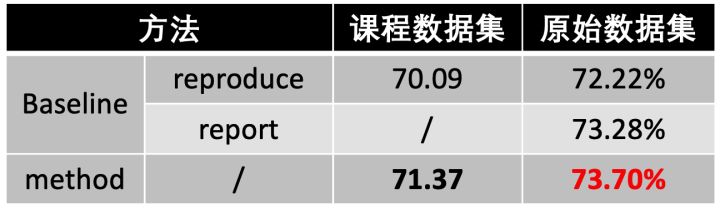
我首先对该Baseline进行复现,作者在GitHub上开源了论文代码[3],我使用原始代码及默认超参数进行复现,结果如下表所示(reproduce表示复现的结果,report表示论文给出的结果)。可以看到,使用Fer2013原始训练集进行训练,可以在其私有测试集上达到72.22%的准确率,比论文中汇报的73.28%要低,只能通过作者提供的预训练权重来达到该准确率。而使用Baseline代码在课程数据集上的训练集上训练,可以在课程验证集上达到70.09%的准确率。

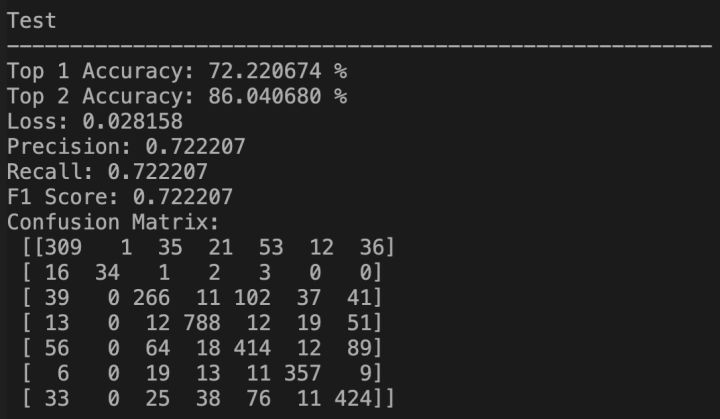
3 方法及实验
首先,根据之前的经验实现一个最基本的分类网络,使用ResNet18作为主干网络,epoch设置为300,batch size为128,损失函数为交叉熵损失,优化器选择SGD,并设置学习率为0.1,momentum为0.9,weight decay为1e-4,并使用了余弦退火学习率衰减策略。
3.1 数据增强
首先,我对数据增强的策略进行探索,对于这种训练集样本数量不够的情况,合适的数据增强策略通常能够很好的提高模型的泛化能力。除此之外,由于Fer2013数据集是通过爬虫进行爬取的数据,因此数据集的差异较大,数据增强也能很好的提高性能。经过尝试与比较,最终使用了如下几种数据增强策略:
- RandomHorizontalFlip:随机水平翻转
- RandomResizedCrop:随机裁剪
- RandomRotation:随机旋转
- ColorJitter:随机颜色抖动
- RandomAffine:随机仿射变换
- RandomErasing:随机图像擦除
并且我通过消融实验,证明了每一种数据增强的策略都确实是能够对性能有所提升,实验结果如下。
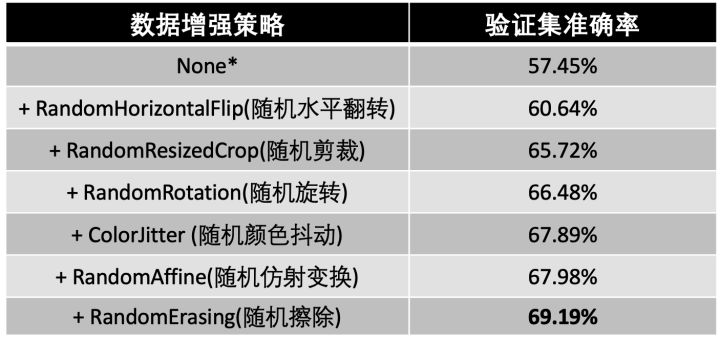
在上表中,当只使用基本的分类网络,不使用任何数据增强策略时,在验证集上只达到了57.45%的准确率。但是,随着数据增强策略的逐渐累加,准确率也有所 提升,其中使用随机剪裁时准确率提升了5.08%左右。最终,在基本分类网络上使用这六种数据增强策略,能达到69.19%的验证集准确率。在下图中,上图为一组原始训练样本,下图为使用六种随机数据增强策略后的训练样本。


3.2 学习率策略
在基本的分类网络中,我凭借之前的做其他分类任务的经验,选择了使用余弦退火学习率衰减策略(CosineAnnealingLR),该策略时让学习率随训练epoch的变化图像类似于余弦函数图像,并结合数据增强策略最终得到了69.19%的准确率。而我注意到baseline方法中使用的学习率策略为ReduceLROnPlateau,该策略可以提前指定某一个性能评价指标(如验证集准确率),当训练过程中该指标不再增大(或减小),则适当的降低学习率。因此,我对两种学习率衰减策略进行了比较,实验结果如下:
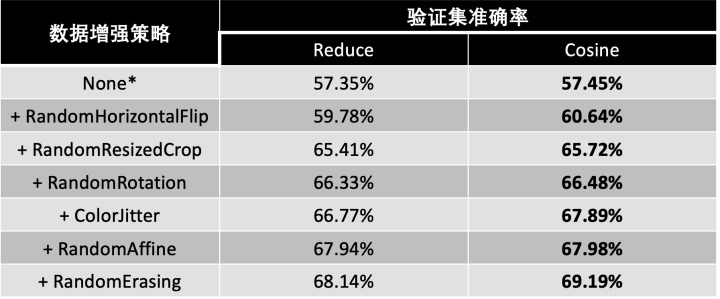
通过对比可以发现,在结合不同的数据增强策略时,使用余弦退火学习率衰减策略比baseline中使用ReduceLROnPlateau策略总能具有更好的性能。
3.3 Label Smooth与Mixup
Label Smooth(标签平滑)是一种正则化的思想,通过对标签的one-hot分布加入一定的噪音分布,从而起到“软化”的效果,防止模型对预测结果过于自信,从而导致过拟合。
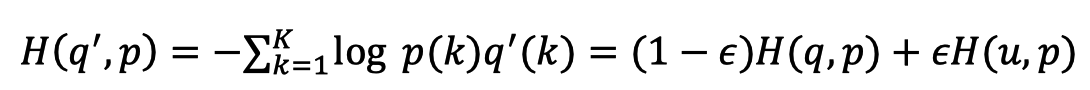
由于Fer2013数据集中存在不少非预期样本(如下图所示),这些样本是不属于任一类别的离群点,因此如果模型过拟合这些样本的话,则会降低泛化能力,从而降低性能。
Mixup则是一种数据增强的思想,它将两张图片按照一定的比例进行融合,同时对它们的one-hot标签也进行同比例的融合:
Mixup的效果如下图所示,通过这样的做法,可以让模型在对一张融合后的样本判断出混合前的两个类别,从而能够提高训练的效果。
我在当前最优的策略上,使用Label Smooth和Mixup策略进行实验,结果如下:
可以看出,在使用数据增强与学习率衰减策略后,单独使用Label Smooth和Mixup都能进一步提高模型在验证集上的准确率。而如果同时使用Label Smooth和Mixup时,在验证集上的准确率均超过了70%,已经与baseline在课程数据集上的性能大致相当。
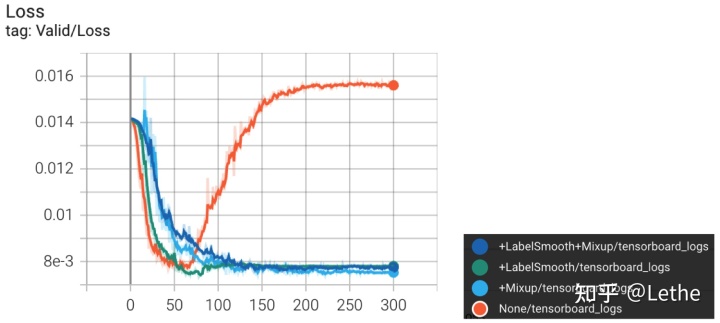
除此之外,通过下图验证集在训练时的Loss曲线可以看出,当不使用Label Smooth和Mixup策略时(橙色曲线),模型随着训练epoch的增加很容易出现过拟合的现象。
3.4 N-Crop
在3.3节中,已经能在课程验证集上达到与baseline方法相当的性能,于是继续尝试使用N-Crop策略,其分为FiveCrop和TenCrop:
(1)FiveCrop: 在图像的左上角、右上角、左下角、右下角和图像中间分别裁剪一个指定大小的子图像,从而将可以将样本数量扩充至原来的五倍
(2)TenCrop: 在FiveCrop的基础上,再将每张子图像进行水平翻转,从而将样本数量扩充至原来的十倍。
这样,当在模型训练的时候使用N-Crop策略,则可以大幅增加训练集的数量,但同时也需要更长的训练时间以及更大的显存;而如果在模型推理时使用N-Crop,则是对多种子图的预测概率去取平均,从而降低模型的错误率。因此,我将N-Crop策略与之前的策略结合,实验结果如下:
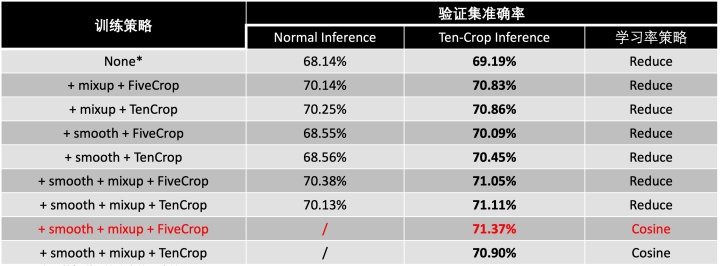
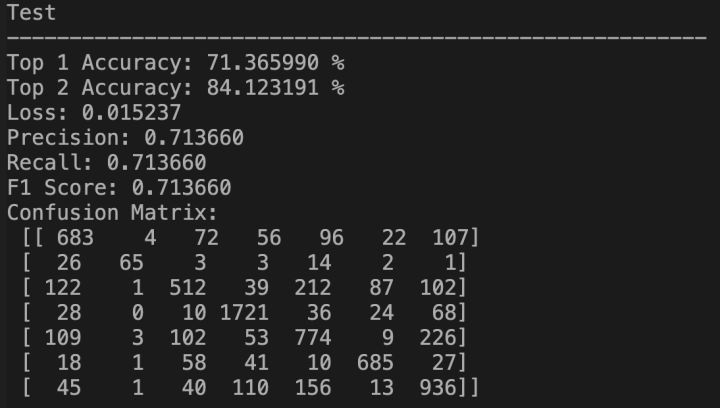
从上表中可以看出,将N-Crop与之前的策略相结合,能够带来性能的提升;并且当在推理的时候使用TenCrop,所有情况下的表现均会更优。最终,在3.4节最优策略的基础上,在模型训练时使用FiveCrop,在模型推理时使用TenCrop,并且使用余弦退火学习率衰减策略时,达到了最优的性能,可以在验证集上达到71.37%的准确率,与Baseline方法在课程验证集上的准确率相比,提升了1.28%。
3.5 模型集成
至此,本次实验已经可以在ResNet18单模型上达到71.37%的验证集准确率,超过了Baseline方法,下面考虑使用集成模型进一步提高准确率。首先,我使用当前最优策略在不同的主干网络上进行实验,得到如下结果:
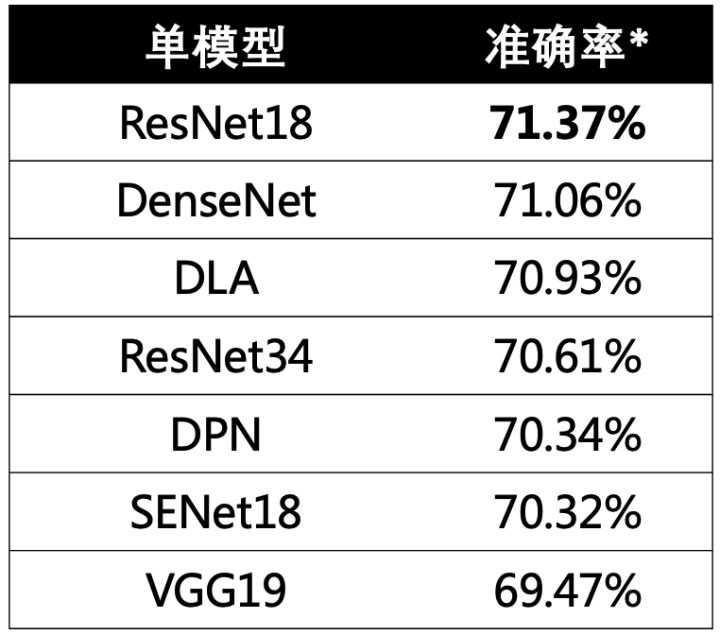
可以看出,最开始选用的ResNet18仍然时性能最好的主干网络,DenseNet、DLA、ResNet34等略低于它。由于时间及显存的限制,我这里仅考虑前四个模型进行集成,并且没有选择投票的集成方式,而是使用了logits融合,结果如下:
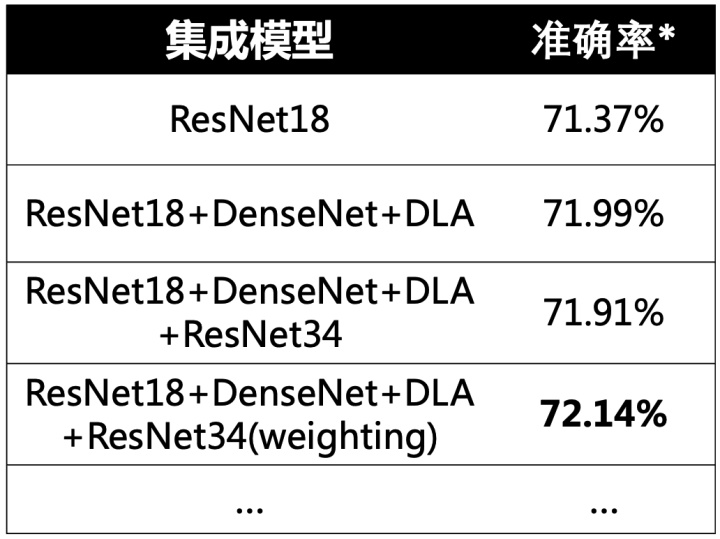
其中,第2行和第4行的集成模型,直接使用logits平均进行集成,性能相较于单模型有所提升。最后一行,则对四个模型的logtis权重进行了一定的调整,最终集成模型可以在验证集上达到72.14%的准确率。另外,本次实验重点放在了单模型的性能提升,对于集成模型的提升并没有做过多的探究。
3.6 其他
除了上述策略之外,我在实验过程也进行了一些其他的尝试:
- 在ResNet18全连接层前加Dropout,效果没有提升的原因可能是Dropout与ResNet中的BN层有一定的冲突[4]。

- 使用带权重的交叉熵损失:用样本数量的倒数作为权重,效果没有提升,可能是因为样本差异实在太大,直接这样子设置权重会损害对样本数量多的类别的学习,也许通过进一步优化权重,可以有所提升。
- 所有试验均固定了随机种子,保证结果可复现性。
- 使用自动混合精度(AMP)训练,从而提高训练速度。
4 原始数据集评估
在第三节中,我通过多种策略的组合与实验,最终在课程数据集的验证集上达到了**单模型71.37%、集成模型72.14%**的准确率,均超过了Baseline。但是由于Baseline的复现结果并不理想,为了更加公平的将本方法与其进行对比。
下面将使用了Fer2013原始数据集对本实验的最优方法进行评估,即在原始训练集上进行训练,以私有测试集的准确率作为评价标准。实验结果如下:
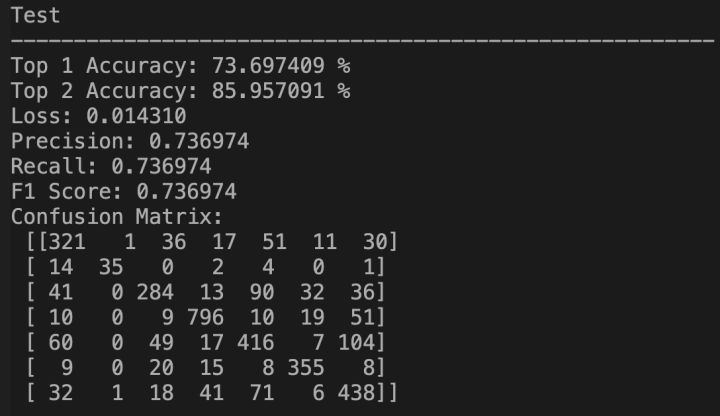
最终,本实验的最优方法在Fer2013原始数据集的私有测试集上达到了73.70%的准确率,超过Baseline方法论文[2]中汇报的73.28%的准确率,达到了目前Fer2013数据集单模型表情识别(不使用额外训练数据)SOTA。并且注意到,我使用的仍是课程数据集下所设置的参数,并没有在原始数据集上进行重新调参,因此可能还有进一步提升的空间。
(手动上榜hhh)
在Fer2013原始数据集上的实验代码及权重已上传至本人GitHub:https://github.com/LetheSec/Fer2013-Recognition-Pytorch
5 总结
(1)本次实验,最终在课程数据集的验证集上使用单模型达到了71.37%的准确率,使用集成模型达到了72.14%的准确率;在原始数据集的私有测试集上单模型达到了73.70%的准确率。
(2)其中73.70%成为Fer2013数据集(不使用额外训练数据)单模型表情识别的新SOTA。
(3)实验没有去耗费大量时间进行调参,大多参数直接进行直觉的选择。
(4)本次实验的重点在单模型的性能提升,并没有过多关注与类别不均衡问题与模型集成的技巧,这也是未来可以进一步改进的地方。
6 参考
[1] https://paperswithcode.com/sota/facial-expression-recognition-on-fer2013
[2] Khaireddin, Yousif, and Zhuofa Chen. “Facial Emotion Recognition: State of the Art Performance on FER2013.” arXiv preprint arXiv:2105.03588 (2021).
[3] https://github.com/usef-kh/fer
[4] Li, Xiang, et al. “Understanding the disharmony between dropout and batch normalization by variance shift.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.