PointRCNN
paper:PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud,CVPR2019
link:https://arxiv.org/abs/1812.04244
code:https://github.com/sshaoshuai/PointRCNN
vedio:https://www.bilibili.com/video/BV1cE411L7mL
1 介绍
PointRCNN是第一个直接基于点云数据的2-state的3D物体检测算法,可以直接从3D点云数据生成候选框,不需要额外的图像输入。
2 方法
整个PointRCNN的框架分为两个部分,上面为stage-1,下面为state-2.
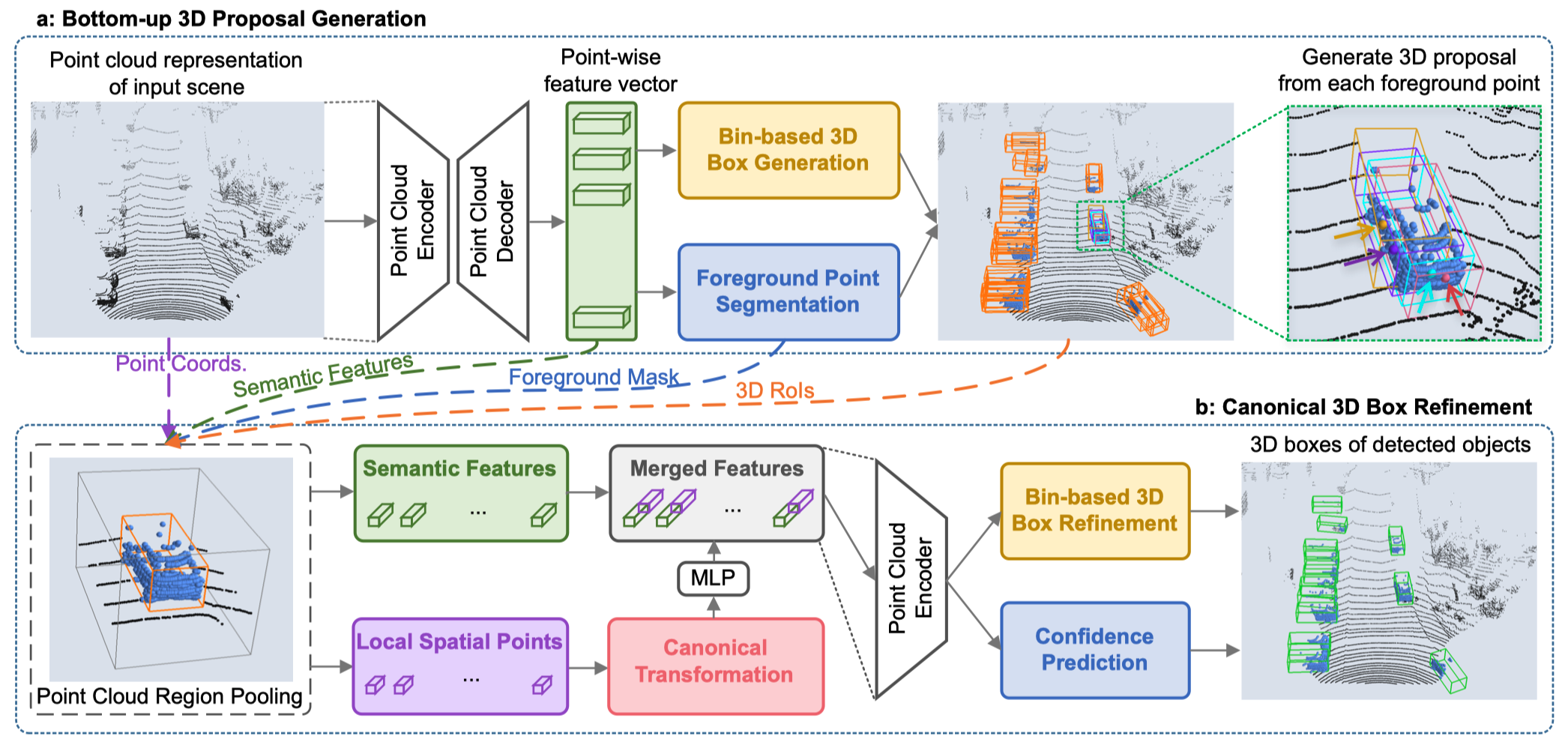
2.1 Stage-1
第一阶段的主要作用是生成候选框,作者直接将原始点云数据输入到PointNet++中得到Point-wise feature vector(每个点的特征向量)。
作者在Backbone后面加了两个分支,分别用于前景点的分割(上图蓝色框Foreground Point Segmentation)和生成3D候选框(上图黄色框Bin-based 3D Box Generation)。
(1)前景点分割(Foreground Point Segmentation):假设目标类别为Car,那么Car中的点就属于前景点,其余属于背景点。那么就可以通过PointNet++生成的特征来预测每一个点属于前景点的概率,此时分割的label来自于训练集中的先验知识,即标注好的3D bounding box中的点为前景点。由于前景点相对于背景点的数量很少,因此作者使用了focal loss来进行类别不均衡的前景点的分割任务。
$$ \begin{aligned} &\mathcal{L}_{\text {focal }}\left(p_{t}\right)=-\alpha_{t}\left(1-p_{t}\right)^{\gamma} \log \left(p_{t}\right) \\ &\text{where} \space p_{t}= \begin{cases}p & \text { for forground point } \\ 1-p & \text { otherwise }\end{cases} \end{aligned} $$**(2)3D候选框生成(in-based 3D Box Generation)**:同时对于每个前景点会预测一个3D proposal候选框(如下图所示,四个不同颜色的点分别生成了一个粗糙的3D候选框)。
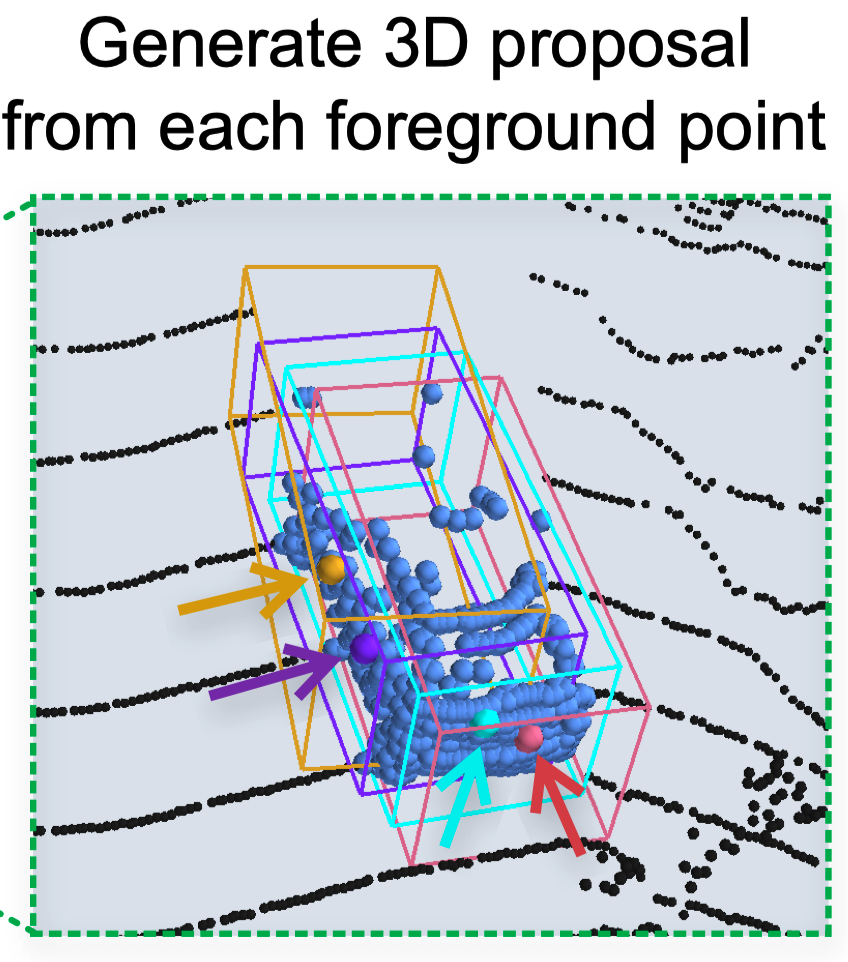
候选框产生的方式为预测每个点bounding box的中心点、朝向角度以及长宽高,同时在这篇文章中提出了一种Bin-Based的3D box生成方式,如下图:
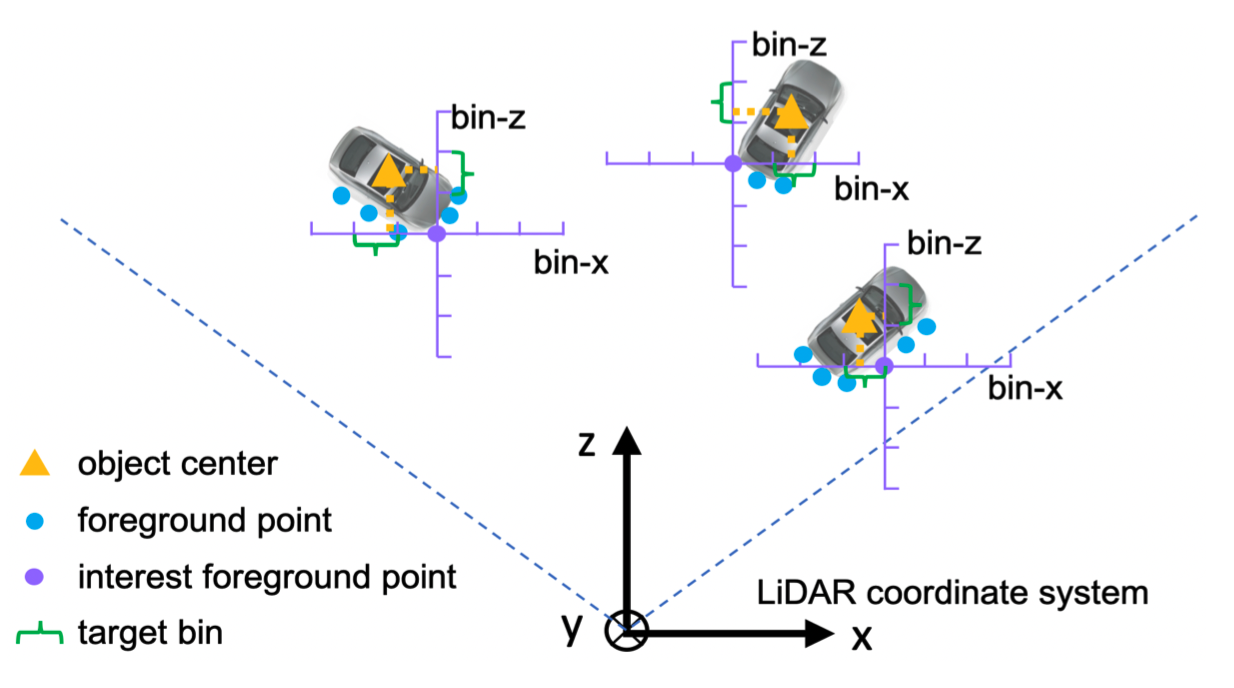
- 这里对每一个前景点生成了一个候选框,传统方法的是对于每个前景点,直接对中心点(黄色三角)的位置做一个回归问题。但是可以看到“车头位置的点”与“车侧面的点”离中心点的距离差异较大,导致了方差是比较大。
- 因此这里提出了Bin-Based 的方法:
- 作者首先在俯视图上将object的区域沿轴切分成了一个个的bin(下图紫色标轴每一个线段代表一个bin)
- 然后预测中心点(黄色三角)相对于每个前景点(紫色点)属于哪一个bin的范围内,这是一个分类问题。
- 最后在每一个bin内再做回归问题来确定中心点的具体位置。
- 这样Bin-based的方法,将一个“回归问题”转变成了“分类+回归的问题”,实验证明可以更快的收敛。另外,作者只是对x轴和z轴上的中线点位置使用了bin-based的方法,y轴(垂直于地面)及长宽高直接用回归进行预测。
- 除此之外,对于旋转角度的预测,作者也适用bin-based的方法,也就是将2$\pi$先分为若干个bin,然后做分类+回归问题。
具体的损失如下:
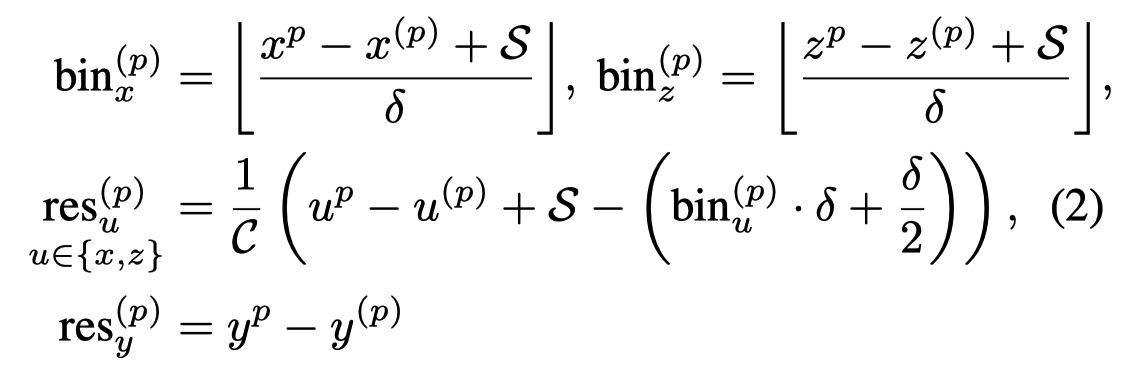
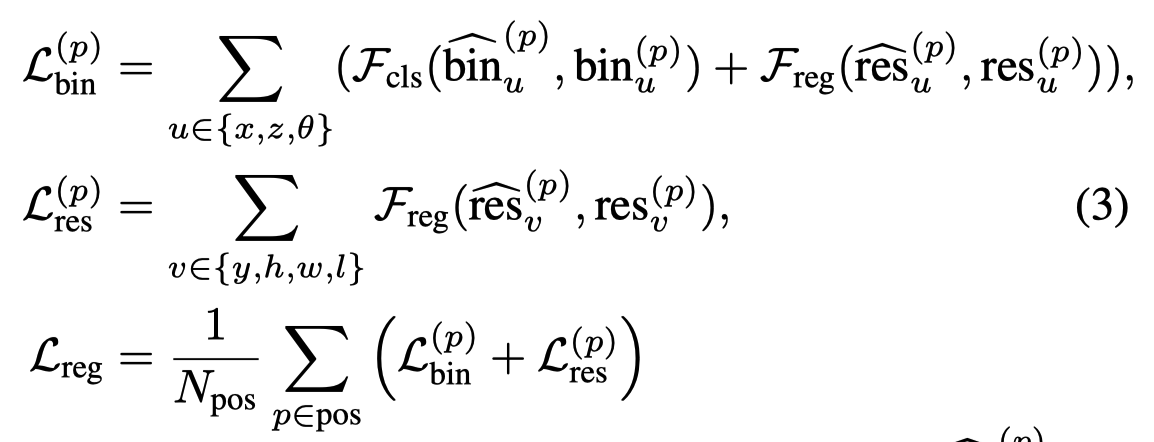
在为每个前景点得到3D Box之后,还需要使用NMS来减少最终proposal bounding box的数量,最终作者选取了300个bounding box作为stage-1阶段生成的候选框。
2.2 Stage-2
第二阶段主要是对第一阶段生成的候选框进行更加精确的打分以及refine:
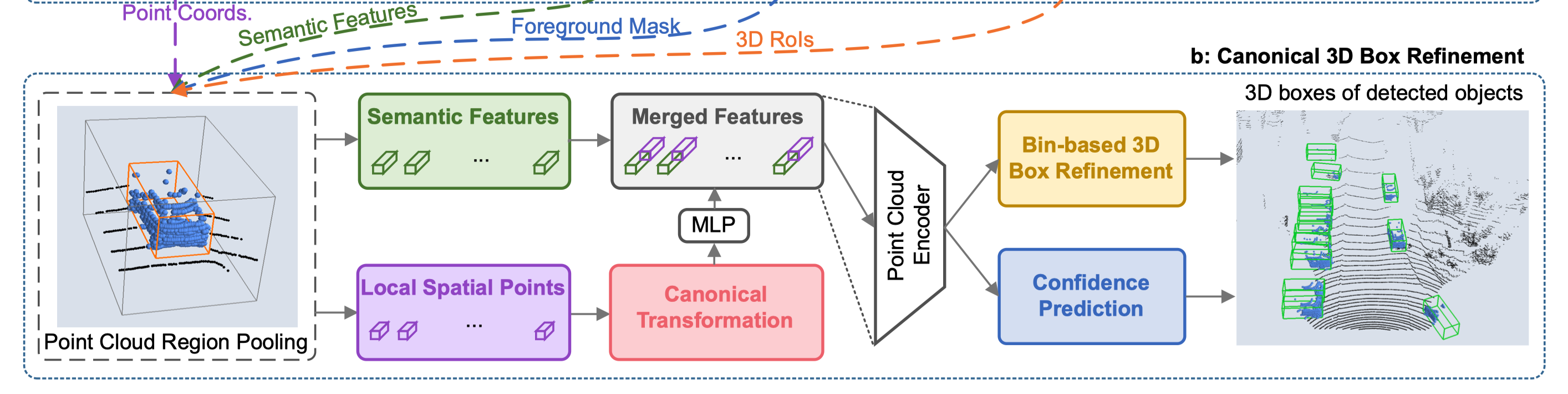
Stage-2的backbone输入来自两部分:
(1)Semantic Feature(上图绿色框)来自于Stage-1的backbone提取的point-wise feature vector,通过stage-1的学习,此时的每个点的特征是包含了一定上下文的信息。
(2)Local Spatial Points(上图紫色框)则是包含了点本身的一些信息,如每个点的坐标位置$(x^{(p)},y^{(p)},z^{(p)})\in \mathbb{R}^3$,每个点的激光反射强度$r^{(p)\in \mathbb{R}}$、第一部中得到的分割信息(即是否为前景点)$m^{(p)}\in {0,1}$。
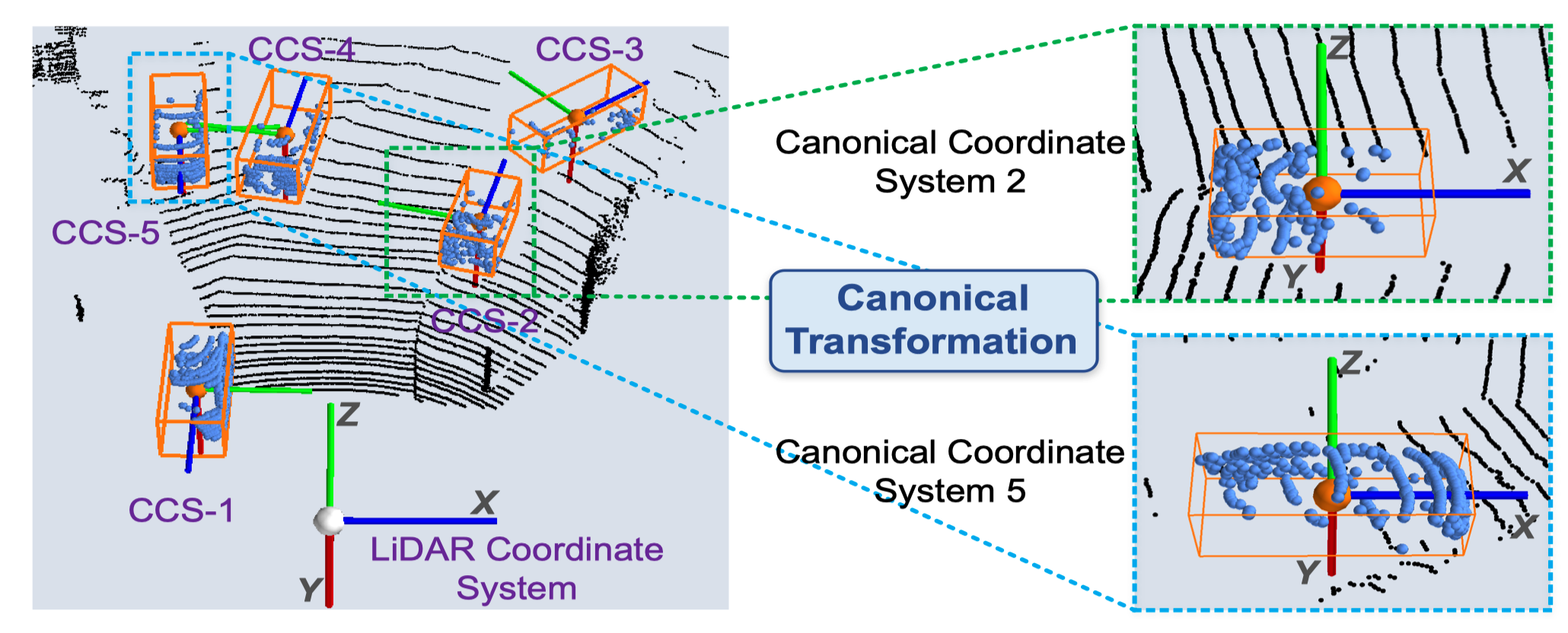
然后作者提出将这些特征做一个Canonical Transformation(上图红色框),如下图所示,也就是对于stage-1生成的每个3d box进行一个坐标系的变换,将不同的候选框变换到统一个坐标系下,具体操作上就是将车头方向都转向同一个方向(如x轴方向),并且以bbox(bounding box)的中心作为坐标轴的原点。
但是这样做很明显会丢失bbox的深度信息,因此作者又在local spatial points加上了每个bbox距离传感器的距离$d^{(p)}=\sqrt{(x^{(p)})^2+(y^{(p)})^2+(z^{(p)})^2}$
最终,作者将Transformation后的Local Spatial Points经过一个MLP升维到与Semantic Features相同的维度,然后进行concat(对于每一个前景点都有一个semantic的feature以及一个local spatial的feature),得到最终的Merged Features(上图灰色框)。
Stage-2依然使用PointNet++作为Backbone,在得到Merged Features后输入到PointNet++的encoder中,编码成单个特征向量,表征了bbox里所有的信息。
然后再经过两个分支:
- Confidence Prediction根据当前表征来对候选框进行一个质量的打分。
- Bin-based 3D box Refinemeant则对该候选bbox进行进一步的refine(再调整一下位置、长宽高之类的),方式与stage-1中的类似,只不过更加精细。
最终,再进行一次NMS将每个object冗余的bbox去掉,只保留一个bbox,得到最终的结果。
3 实验结果
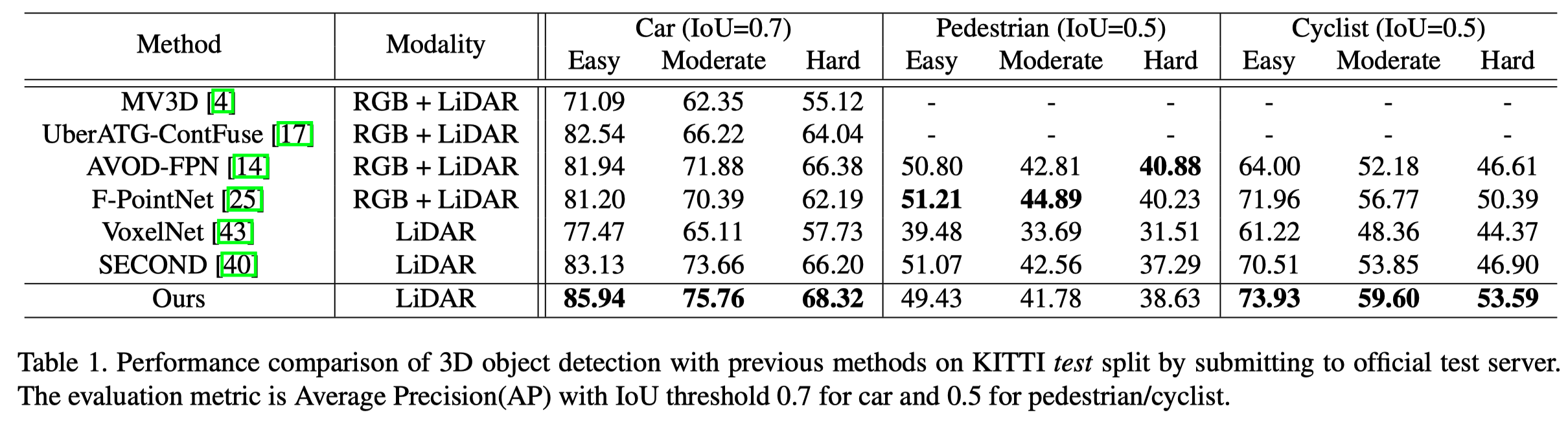
第二列表示使用的输入数据信息,在使用纯LiDAR的方法里有很大提升
第三列表示对于Car类的检测结果(PointRCNN主要是对Car类进行的调参)
- IoU=0.7表示,当预测的bbox与target bbox的IoU大于0.7就表示预测正确,因此越低表示越容易。
- Easy、Moderate、Hard分别是KITTI划分的难度的子集(如有些object被遮挡或截断,就提高了难度)。
PointRCNN在测试集上的预测结果:
